Module 13 Multivariate data analysis
13.1 Multivariate data
13.1.1 Univariate vs. multivariate data
Things are not always one or two dimensional. Oftentimes in biology we need to consider many variables at once. This is the realm of multivariate statistics. The “multi” in “multivariate” refers to the fact that there are multiple variables or attributes of each sample that we want to understand simultaneously. The terminology can be confusing sometimes because other statistical methods have the word “multiple” in their names. For example, “multiple linear regression” is not considered a multivariate method because there is only one measurement from each sample (the response variable) that is being modeled.
The figure below shows some differences between a univariate analysis and a multivariate one. In the univariate analysis, one and only one variable is the response variable and is assumed to be predicted by (aka: depend on) the others. Frequently, the observations are divided a priori into groups by a factor encoded by one of the predictor variables. This means that the goal of a univariate analysis is to explain patterns in one variable relative to other variables. In a univariate analysis, the emphasis is on discovering relationships between variables, and the observations are a means to that end.
In a multivariate analysis, none of the variables are singled out and all are of interest for explaining differences or similarities between the observations. The observations may come from a priori groups defined in a separate matrix (see below), or the researcher may want to discover how the observations naturally separate into clusters based on the variables (i.e., a posteriori groups). Or, the researcher may want to know which variables, if any, drive most of the variation between observations. The key is that in a multivariate analysis the emphasis is often on discovering patterns between observations, and the variables are a means to that end.

13.1.2 Components of multivariate data
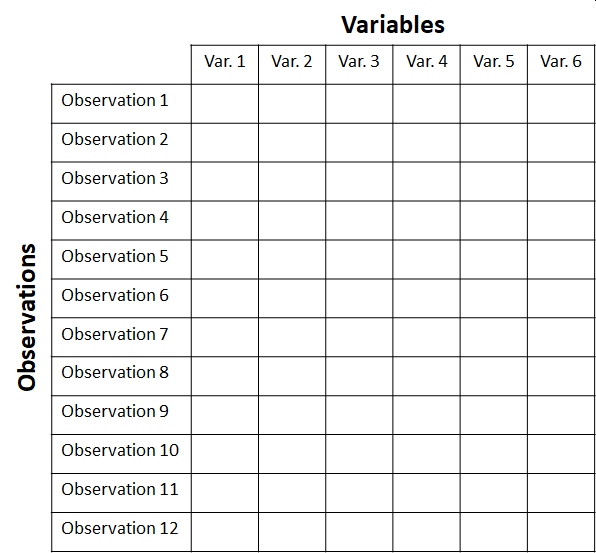
When planning and executing a multivariate analysis it is very important to keep in mind which components of the dataset are which. These components are usually stored in matrices with a well-defined structure. The key concept is that of the sample unit or observation. These are individual observations about which many measurements or attributes are recorded. Sample units correspond to rows of the data matrix. Each sample unit has several attributes or variables associated with it. Variables correspond to columns of the data matrix. The figure below shows the layout of a typical multivariate dataset. The example has 12 observations and 6 variables . In some fields, samples are also called records and variables are called features.
Complex datasets often contain data of different types, or sets of variables that capture information about different aspects of the system. For example, you might have variables that contain species abundances, optical densities, concentrations, femur lengths, treatment groups, and so on. When planning a multivariate analysis you need to consider whether and which variables should be grouped together. In an exploratory analysis, perhaps all of the variables are of interest and no subgroups are needed. In many situations, some of the variables will be the “response” variables. These contain the patterns that you are interested in explaining. Other variables might be considered “explanatory variables”. These are variables that may or may not help explain some of the patterns in the first set of variables. Other variables might contain information about the response variables. For all variables except the first set of “response” variables, the key is whether the values are associated with rows of the main data matrix shown above (i.e., with observations), or whether the values are associated with columns of the main data matrix (i.e., with other variables).
The figure below shows the relationship between three interrelated matrices typical in community ecology. Similar matrices can be defined for other fields…just replace “Environmental variables” with another label that helps describe variation among the sample units.
- The data matrix A contains data on the abundance of 6 species at each of 12 sites.
- The explanatory matrix E contains 4 environmental variables (e.g., temperature, latitude, etc.) for each of the sites. These data describe relationships between observations in A.
- The trait matrix S contains data about traits (e.g., maximum size, longevity, etc.) of the species in the main matrix. These data describe relationships between variables in A.
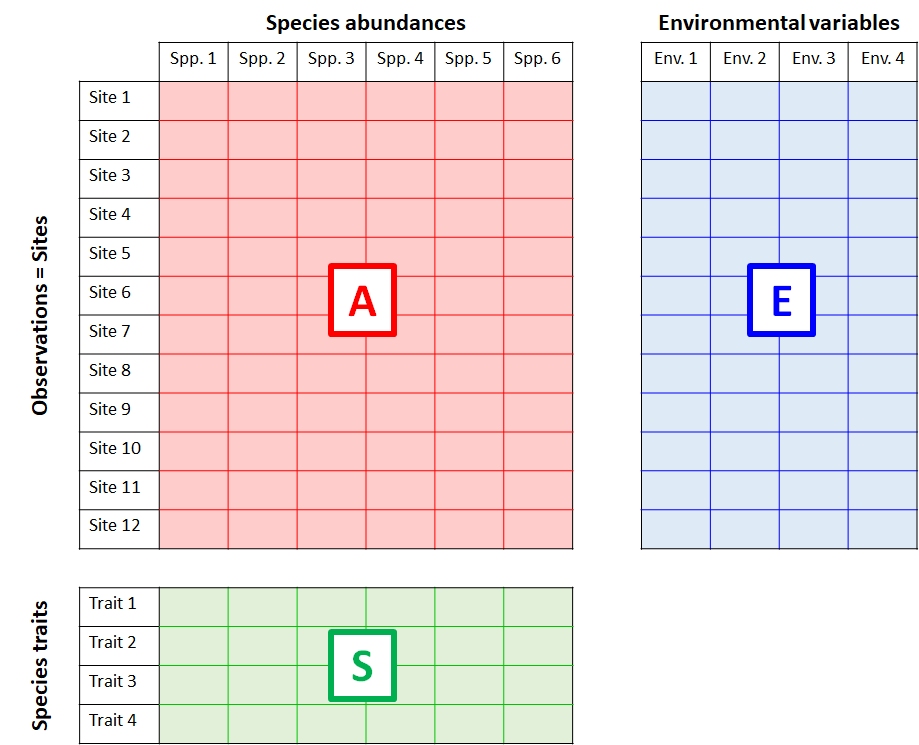
A biological system of interest might have relationships among all three of these matrices:
- Patterns within A: Explaining groupings or trends among the sites in terms of the species present or absent at each site (or, the abundances of species at each site).
- Patterns within E: Discovering groupings among the sites in terms of their environmental variables.
- Relationships between A and E: Relating patterns in environmental variables to patterns in species abundances across sites.
- Relating patterns between A and E in terms of S: Relating species traits to environmental conditions.
- Patterns within S: Identifying clusters of similar species.
McCune et al. (2002) give a thorough treatment of the relationships between S, E, A, and other matrices derived from them. For this course, we will focus on analyzing A and sometimes E. There is a related set of terminology used to describe multivariate analyses in terms of what is being compared. Analyses that seek relationships among samples are said to be in Q mode; analyses that seek relationships among variables are in R mode (Legendre and Legendre 2012). These terms appear to be particular to ecology, but offer a helpful way to distinguish between different multivariate analysis pathways.
13.2 Distance metrics: biological (dis)similarity
One of the central questions in a multivariate analysis is, “How similar to each other are my samples?” This is a more complicated question than it appears. It’s worth considering for a moment what “similar” even means. Consider the set of organisms below. How would you group them by “similarity”?

Here is one way:

You might have come up with a slightly different set of groupings. This one is just as valid:

These examples illustrate how we might classify the organisms based on qualitative characteristics. But do our choices weight each characteristic equally? After all, fungi and plants are far more different from each other than ants and fish, but the second scheme lumps all non-animals together. Which characteristics of the organisms are really driving our classification decisions?
One way around this problem is to assign numeric scores to characters: 1 if an organism has the trait, and 0 if it doesn’t. The table below illustrates this for a few organisms and characteristics. Note that bacteria have NA for hetertrophy, becuase many bacteria are also autotrophs.
| Taxon | Multicel. | Heterotroph. | Flower. | Vert. | Gills | Amnion | Endotherm. |
|---|---|---|---|---|---|---|---|
| Bacteria | 0 | NA | 0 | 0 | 0 | 0 | 0 |
| Maple | 1 | 0 | 1 | 0 | 0 | 0 | 0 |
| Pine | 1 | 0 | 0 | 0 | 0 | 0 | 0 |
| Octopus | 1 | 1 | 0 | 0 | 1 | 0 | 0 |
| Shark | 1 | 1 | 0 | 1 | 1 | 0 | 0 |
| Mushroom | 1 | 1 | 0 | 0 | 0 | 0 | 0 |
| Frog | 1 | 1 | 0 | 1 | 0 | 0 | 0 |
| Elephant | 1 | 1 | 0 | 1 | 0 | 1 | 1 |
| Penguin | 1 | 1 | 0 | 1 | 0 | 1 | 1 |
| … |
The full table for our organisms has more columns and rows (we’ll get to that later).
The next step is to somehow quantify the similarities between the organisms. It turns out that it’s easier to define dissimilarity than it is define similarity. This is because the range of a similarity metric is ill-defined: there is no natural value to assign to identical samples. I.e., what value should identical samples have? Infinity? Some other arbitrary value? The first isn’t very useful, and the second is highly subjective. Dissimilarity, on the other hand, has a natural value to assign to identical samples: 0. Dissimilarity is often expressed as a distance through a hyperspace. Hyperspace in this context means a coordinate system with one axis (dimension) for each variable in the data.
To quantify distances between taxa, we might try adding up the differences between each pair. We should also square each individual difference, so \(1-0\) counts the same as \(0-1\). Then, we add up the squared differences and take the square root to get back to the original scale. For example, the distance between maple and pine in the table above would be:
\[ D(maple,pine)=\sqrt{(1-1)^{2}+(0-0)^{2}+(1-0)^{2}+(0-0)^{2}+(0-0)^{2}+(0-0)^{2}+(0-0)^{2}}=1\]
The difference between octopus and penguin would be:
\[ D(octopus,penguin)=\sqrt{(1-1)^{2}+(1-1)^{2}+(0-0)^{2}+(0-1)^{2}+(1-0)^{2}+(0-1)^{2}+(0-1)^{2}}=1\]
And the difference between mushrooms and elephants is:
\[ D(mushroom,elephant)=\sqrt{(1-1)^{2}+(1-1)^{2}+(0-0)^{2}+(0-1)^{2}+(1-0)^{2}+(0-1)^{2}+(0-1)^{2}}\approx1.73\]
So, for this set of characteristics, octopuses and penguins are twice as different from each other as are maple trees and pine trees, while mushrooms and elephants are not quite as different from each other as octopuses and penguins. Interestingly, mushrooms and elephants are more different from each other than are maples and pines, even though maples and pines are in the same kingdom while mushrooms and plants are not. Does that make sense biologically?
These comparisons were chosen to make a couple of points about quantifying differences. First, the choice of characteristics (or measurements, or metrics, etc.) has a large influence over the calculation. Look over the list again and ask yourself if those characteristics are applicable to all of the organisms. Four of the eight traits are specific to just the animals! Second, the choice of how to combine the differences makes a big difference. There are other methods we could have chosen (see below) that might have measured dissimilarity differently.
13.2.1 Euclidean distance
The most basic distance metric is the Euclidean distance. This is a generalization of the Pythagorean theorem to an arbitrary number of dimensions. The calculations above were presented in a cumbersome way to show how they work, but the Euclidean distance metric is usually written in a more compact format:
\[D(x_{i},x_{h})=\sqrt{\sum_{j=1}^{p}(x_{i,j}-x_{h,j})^{2}} \]
In this expression the difference between observation i and observation h (\(x[i]\) and \(x[h]\)) is the square root of the sum of squared differences between \(x_{i}\) and \(x_{h}\) in terms of each variable j, up to the number of variables p. When p = 2, this formula reduces to the Pythagorean theorem:
\[D(x_{i},x_{h})=\sqrt{\sum_{j=1}^{2}(x_{i,j}-x_{h,j})^{2}}=\sqrt{(x_{i,1}-x_{h,1})^{2}+(x_{i,2}-x_{h,2})^{2}} \]
Again, the Euclidean distance is just the Pythagorean theorem generalized to p dimensions rather than the usual 2. One way to think of the Pythagorean theorem is as the distance between points on the 2-d plane, with the x and y coordinates as the side lengths of the triangle.
Here and for the rest of this course, “dimension” means the same as “variable”. When thinking about multivariate statistics, it can be useful to think of your data as defining a hyperspace or hypervolume, with one dimension for each variable in your data. Thus a dataset with 2 variables defines a space with 2 dimensions (i.e., a plane); a dataset with 3 dimensions defines a space with 3 dimensions (i.e., a volume), and so on. When discussing multivariate differences between sample units, we usually refer to the differences as distances through these hyperspaces. Each distance metric calculates that distance a slightly different way.
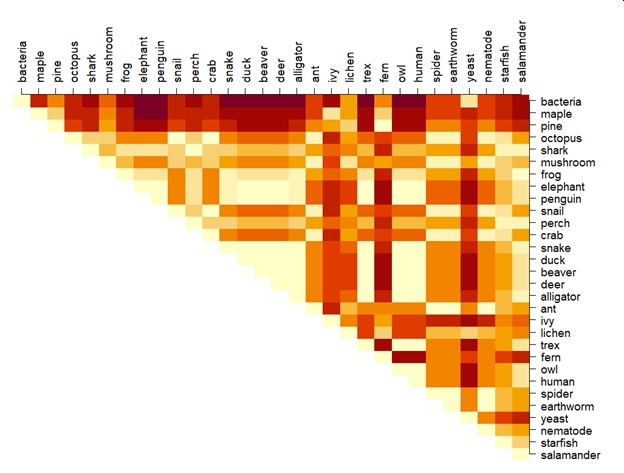
Back to our organism classification example, the figure below shows Euclidean distances for 30 organisms across 12 traits. The distances are distances between each of the 435 unique pairs of taxa in a 12-dimensional hyperspace. Darker colors indicate greater distance—i.e., greater dissimilarity or smaller similarity.
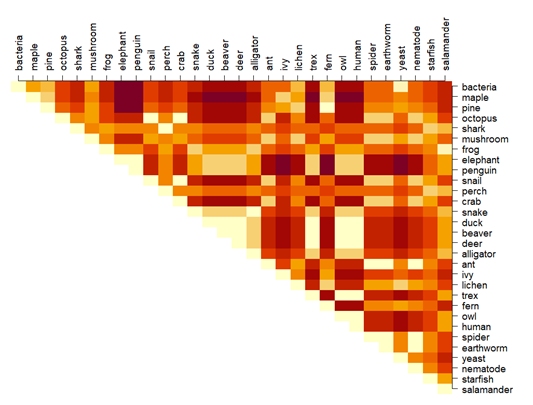
If you examine the chart above you will find that some if the distances are silly: for example, octopuses are presented as more different from owls than they are from bacteria. This suggests that the Euclidean distance metric was maybe not the right one.
13.2.2 Bray-Curtis and other distance metrics
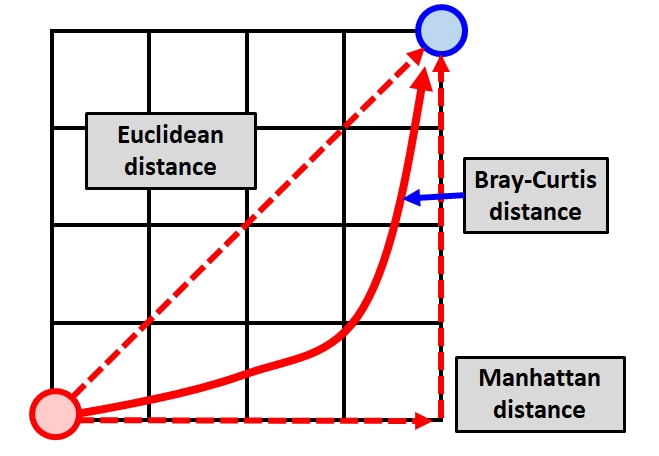
Another distance metric is called the Manhattan or city block distance. It gets its name from the way that distances are added up by assuming that samples can only be connected by paths that move along one axis (i.e., dimension) at a time. This is analogous to how people in cities can walk along the sidewalks of the city street grid, but cannot cut through blocks. The figure below illustrates this.
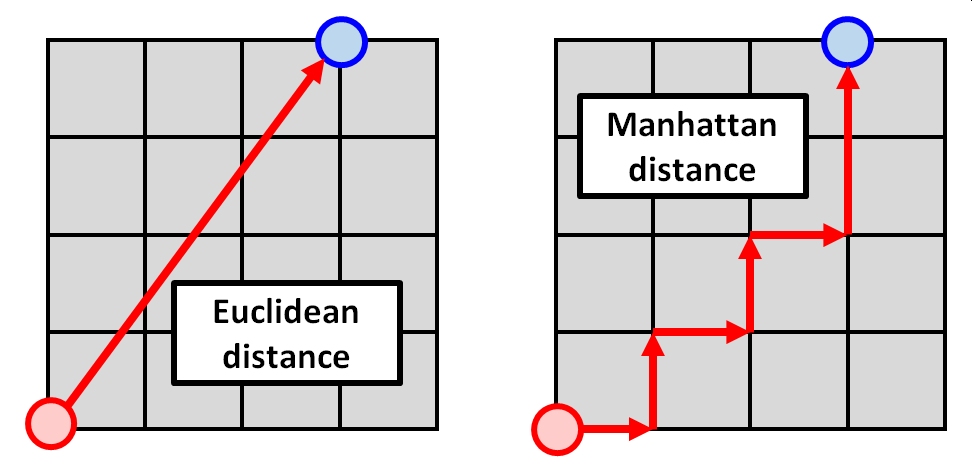
The Manhattan distance is longer than the Euclidean distance, but it can sometimes be a better representation of the differences between sample units in terms of many variables. The Manhattan distance is calculated as:
\[D(x_{i},x_{h})=\sum_{j=1}^{p}|x_{i,j}-x_{h,j}|\]
The Manhattan distance is not often used by itself, but a relativized version of it is extremely common in biology: the Bray-Curtis distance, also known as the Sørenson distance. This distance measure is called the Sørenson index when used with binary data (such as 1/0 for presence/absence). The name Bray-Curtis is used when the same formula is applied to continuous data (often proportions or percentages). The Bray-Curtis distance is calculated as:
\[D_{BC}(x_{i},x_{h})=\frac{\sum_{j=1}^{p}|x_{i,j}-x_{h,j}|}{\sum_{i=1}^{p}x_{i,j}+\sum_{i=1}^{p}x_{h,j}}=1-\frac{2\sum_{j=1}^{p}MIN(x_{i,j},x_{h,j})}{\sum_{i=1}^{p}x_{i,j}+\sum_{i=1}^{p}x_{h,j}}\]
In the second expression, MIN() is a function that returns the smaller of two values. Notice that the Bray-Curtis distance is essentially the Manhattan distance divided by the shared total values in both samples. This ratio can be thought of as the shared values divided by the total of values. The division makes this value “relativized” (i.e., relative to something else, in the same way that percentages are relative to 100). The figure below shows the approximate relationship between the Euclidean distance, Manhattan distance.
If we recalculate the distance matrix between the taxa in our example, the distances now look like this:
The new distances are an improvement but there is still a lot of room to get better. For example, salamanders are more similar to pines than they are to maples. I’ll leave the interpretation of that finding up to you (hint: there isn’t one…this is a silly example).
There are lots of other distance metrics, but a full exploration is beyond the scope of this course. The table below, adapted from McCune et al. (2002), gives some characteristics of some common measures. The range of input data x and distance measures d is provided. For most biological situations where data are nonnormal and relationships are nonlinear, the Bray-Curtis distance is likely to be the most appropriate. When many variables contain lots of 0s, a modified version can be used that adds a “dummy species” present in every sample to stabilize the distances (Clarke et al. 2006). The Euclidean metric has strong requirements of multivariate normality and collinearity among variables; the Bray-Curtis metric does not. The other metrics aren’t as commonly used as the Euclidean and Bray-Curtis, but are included here for reference.
| Metric | Domain of x | Range of d | Comments |
|---|---|---|---|
| Bray-Curtis (Sørenson) | \(x \le 0\) | \(0 \le d \le 1\) | Preferred in many biological situations |
| Relative Sørenson (Kulczynski) | \(x \le 0\) | \(0 \le d \le 1\) | Relativized by sample totals |
| Jaccard | \(x \le 0\) | \(0 \le d \le 1\) | Related to Manhattan distance |
| Euclidean (Pythagorean) | \(x \in \mathbb{R}\) | \(0 \le d\) | Often requires multivariate normality |
| Relative Euclidean (chord distance) | \(x \in \mathbb{R}\) | \(0 \le d \le \sqrt{2}\) or \(0 \le d \le 2\) | Euclidean distance on a hypersphere |
| Chi-square | \(x \ge 0\) | \(0 \le d\) | Euclidean but weighted by sample and variable totals |
| Squared Euclidean | \(x \in \mathbb{R}\) | \(0 \le d\) | Square of Euclidean distance |
| Mahalanobis | \(x \in \mathbb{R}\) | \(0 \le d\) | Distance between groups weighted by intragroup variance |
Remember that distances express differences between samples with respect to several variables. This can be visualized as a distance through a hyperspace with as many dimensions as you have variables. As we’ll see in the next section, we can use distances to explore similarities and differences between samples.
13.3 Clustering
Now that we have a way of quantifying multivariate differences between samples as distance, we can use those measures to explore patterns in data. One application of distance metrics is to use them to organize data into clusters or groups consisting of samples that are more similar to each other than they are to other samples. In other words, the within-group distances should be smaller than the between-group distances. The figure below illustrates this concept with an imaginary example. The clusters shown cleanly separate black, red, and blue points. For example, the average distance between the black points is smaller than the average distance between the black points and the red or blue points. Likewise, the average distance between the red points is smaller than the average distance between the red points and the black points or the blue points.
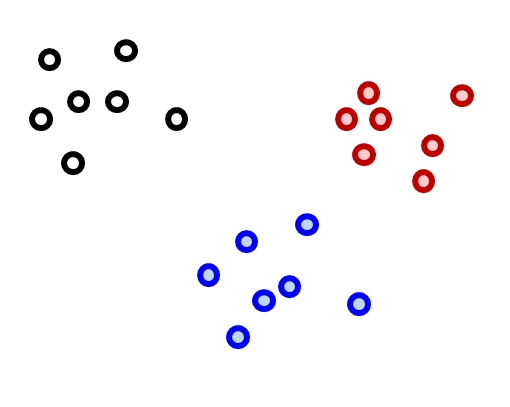
There are many methods for clustering observations. Many methods are hierarchical, with groups being nested within other groups. Hierarchical methods are often the most useful for biologists, because so many of the phenomena we study have some hierarchical nature to them. Other methods are nonhierarchical. Both approaches work by minimizing within-group distances relative to between group distances. The difference is that hierarchical methods have the constraint that larger groups are formed from subgroups.
Clustering methods also differ in their manner of group construction. Many methods are agglomerative, which means that groups are formed by combining samples. Other methods are divisive, which means that all samples start in a single group which is then broken up. Examples of each class of clustering method are shown below.
| Group nature | Group formation | Common methods |
|---|---|---|
| Nonhierarchical | Agglomerative | ?? |
| Nonhierarchical | Divisive | K-means clustering |
| Hierarchical | Agglomerative | Ward clustering (Ward 1963) |
| Hierarchical | Divisive | Association analysis (Ludwig et al. 1988, Legendre and Legendre 2012); TWINSPAN (Hill 1979, Roleček et al. 2009) |
13.3.1 K-means clustering
K-means clustering is a method for dividing a dataset with n observations, with p variables, into k categories such that each observation belongs to the cluster with the most similar mean . The “mean” for each category (i.e., group) is really a position in a p-dimensional hyperspace called a centroid. In this context, centroids are calculated as the point at the central coordinate of each dimension. The mean is most often used, but the median can be a useful alternative.
There are several algorithms for k-means clustering. One of the most common works like this:
- Select the desired number of clusters k.
- Make an initial guess of the mean of each cluster. I.e., Start with a k random positions in the p-dimensional hyperspace. These positions are known as centroids.
- Calculate the Euclidean distance between each sample and each centroid.
- Assign each sample to the category corresponding to the nearest centroid.
- Update the centroids for each cluster by calculating the new centroid for the samples assigned to each cluster.
- Repeat steps 3, 4, and 5 until cluster assignments no longer change.
This algorithm is not guaranteed to find the best possible solution, but it quite often finds decent solutions. Distance metrics other than the Euclidean can be used, but Euclidean is most common. Transforming, scaling, and/or standardizing variables so that they are all on the same scale can improve the results.
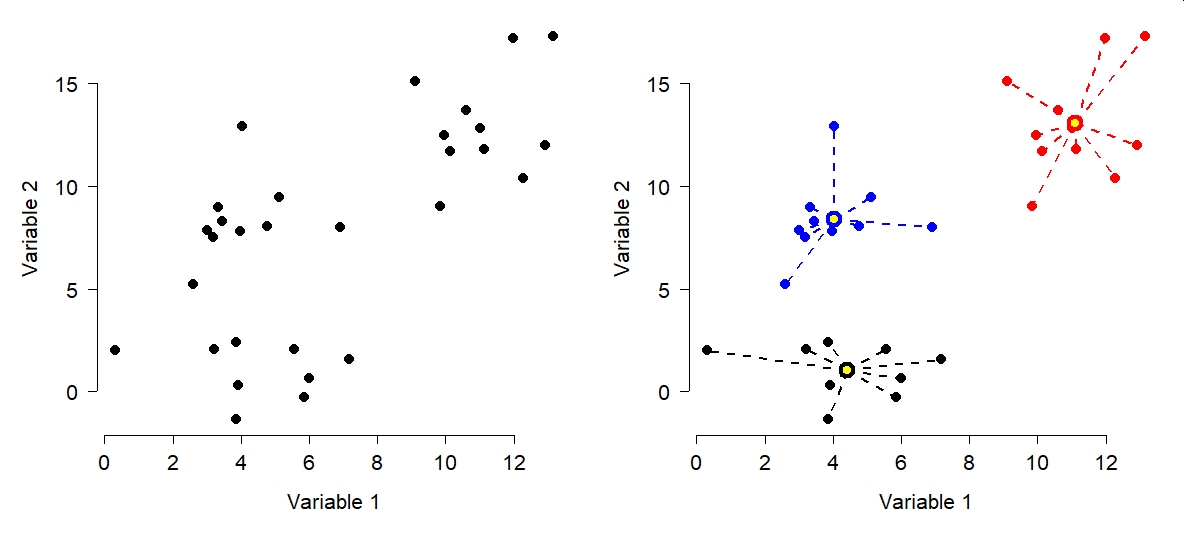
The figure below shows the effects of k-means clustering on a pretend dataset with 2 variables with \(k = 3\). The group assignments were determined because groups with those centroids had the smallest possible set of Euclidean distances between the points and the group centroids (right panel). Group centroids are added to the plot in yellow.
How many clusters are appropriate? That’s a good question to ask, and sometimes a tricky question to answer. One common way to assess the optimal k is to try several k and calculate the within-cluster sum of squared errors (WSS) for all points. The optimal value of k is the value at which a plot of WSS vs. k starts to bend. The example below illustrates this method for the data above.
# generate a random dataset with 3 clusters
set.seed(1234)
x <- c(rnorm(20, 5, 2), rnorm(10, 12, 2))
y <- c(rnorm(10, 3, 2), rnorm(10, 10, 2), rnorm(10, 14, 2))
dat <- data.frame(x,y)
# perform k-means clustering with k from 2 to 8
kvec <- 2:8
nk <- length(kvec)
k.list <- vector("list", nk)
for(i in 1:nk){
k.list[[i]] <- kmeans(dat, kvec[i])
}
# gather WSS for each k
wss <- sapply(k.list, function(x){x$tot.withinss})
# plot WSS vs. k
par(mfrow=c(1,1))
plot(kvec, wss, type="o", lwd=3, pch=1.5,
xlab="Clusters (k)",
ylab="Total WSS")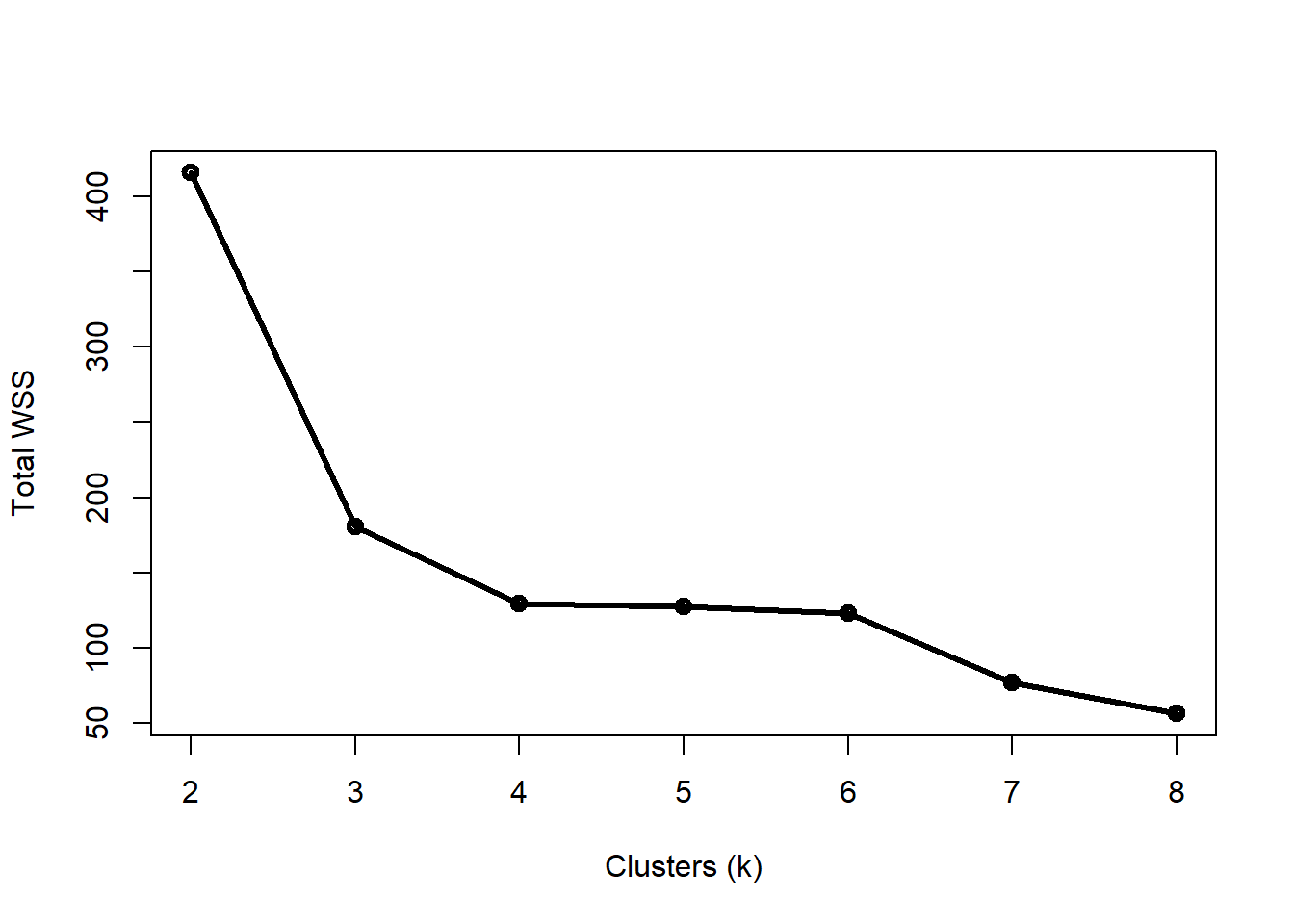
Notice that total WSS drops off much more slowly above 3 clusters. That is, going from 3 to 4 clusters reduces WSS much less than going from 2 to 3 clusters. The result above could reasonably justify 3 or 4 clusters. The figure below shows how the data are divided into 3 and 4 clusters.
# assemble values needed for plots
## get clusters
dat$k3 <- k.list[[which(kvec == 3)]]$cluster
dat$k4 <- k.list[[which(kvec == 4)]]$cluster
## coordinates of group centroids
km3 <- k.list[[which(kvec == 3)]]
km4 <- k.list[[which(kvec == 4)]]
dat$cenx3 <- km3$centers[dat$k3,1]
dat$ceny3 <- km3$centers[dat$k3,2]
dat$cenx4 <- km4$centers[dat$k4,1]
dat$ceny4 <- km4$centers[dat$k4,2]
## colors for each group
dat$col3 <- rainbow(3)[dat$k3]
dat$col4 <- rainbow(4)[dat$k4]
# make plot
par(mfrow=c(1,2))
plot(x,y, pch=16, col=dat$col3, cex=1.4,
xlab="Variable 1", ylab="Variable 2",
main=expression(italic(k)==3))
segments(dat$cenx3, dat$ceny3, dat$x, dat$y,
col=dat$col3, lwd=2, lty=2)
points(dat$cenx3, dat$ceny3, pch=21, cex=2,
bg="yellow", col=dat$col3, lwd=4)
plot(x,y, pch=16, col=dat$col4, cex=1.4,
xlab="Variable 1", ylab="Variable 2",
main=expression(italic(k)==4))
segments(dat$cenx4, dat$ceny4, dat$x, dat$y,
col=dat$col4, lwd=2, lty=2)
points(dat$cenx4, dat$ceny4, pch=21, cex=2,
bg="yellow", col=dat$col4, lwd=4)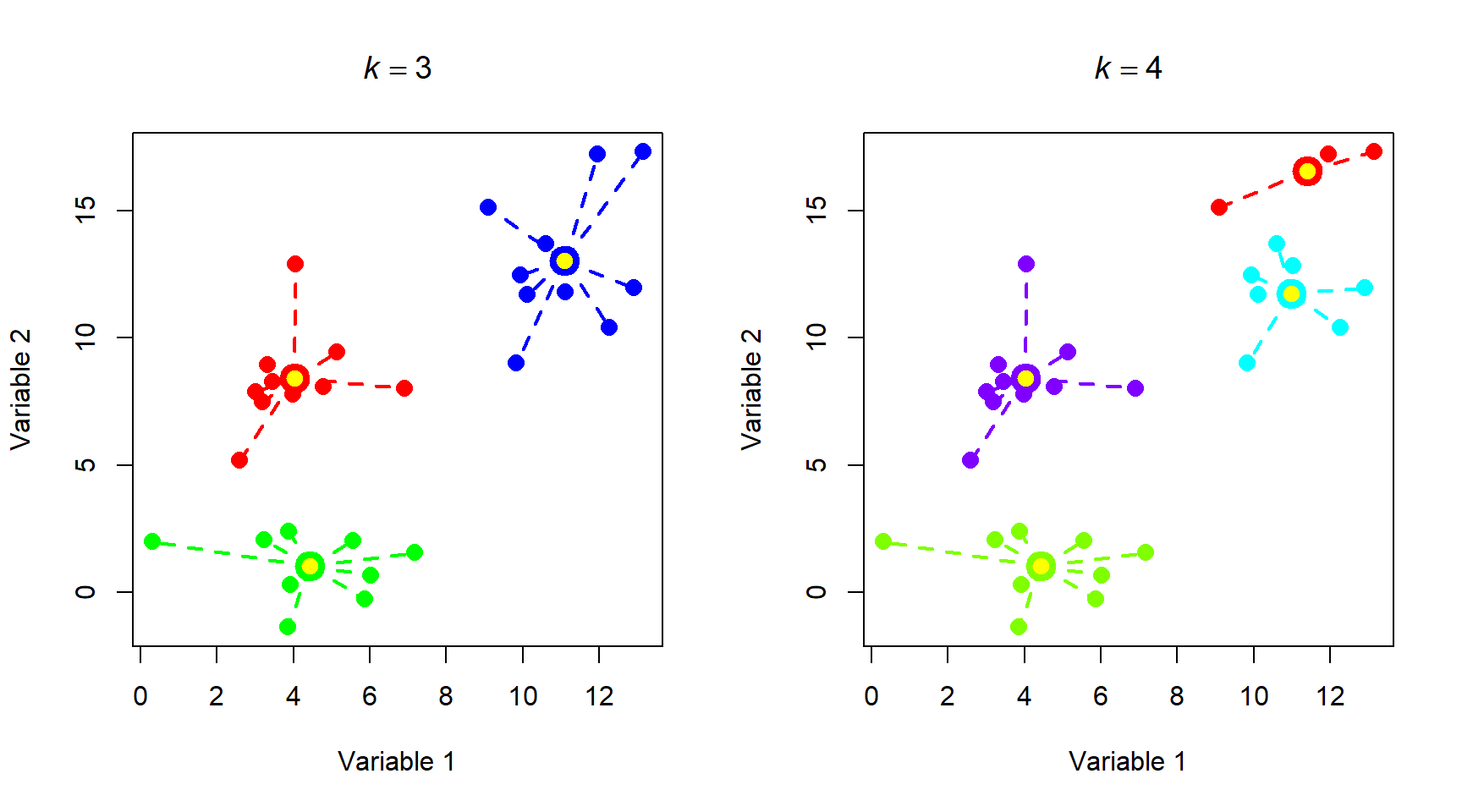
Most of the group assignments stayed the same, but the algorithm split the blue group when k increased from 3 to 4. Accepting the 3 cluster or 4 cluster solution is as much of a biological decision as it is a statistical one. When you get to this point, you need to think about whether the groups make sense or not. Notice that k-means clustering does not necessarily result in groups of equal sizes. This may or may not be a problem depending on the structure of your dataset and the question you are trying to answer.
Below is another example of k-means clustering applied to the taxonomy dataset from above. Examine the figure and ask yourself whether the groupings make sense from a biological perspective. Note that the code block below requires that you have the data file tax_example_2021-10-27.csv in your R home directory. Download it here. Note that this is a completely made-up dataset, so you should not use it for anything important.
set.seed(123)
in.name <- "tax_example_2021-10-27.csv"
dat <- read.csv(in.name, header=TRUE)
rownames(dat) <- dat$organism
dat$organism <- NULL
kvec <- 2:8
nk <- length(kvec)
k.list <- vector("list", nk)
for(i in 1:nk){
k.list[[i]] <- kmeans(dat, kvec[i])
}
wss <- sapply(k.list, function(x){x$tot.withinss})
par(mfrow=c(1,1))
plot(kvec, wss, type="o", lwd=3, pch=1.5,
xlab="Clusters (k)",
ylab="Total WSS")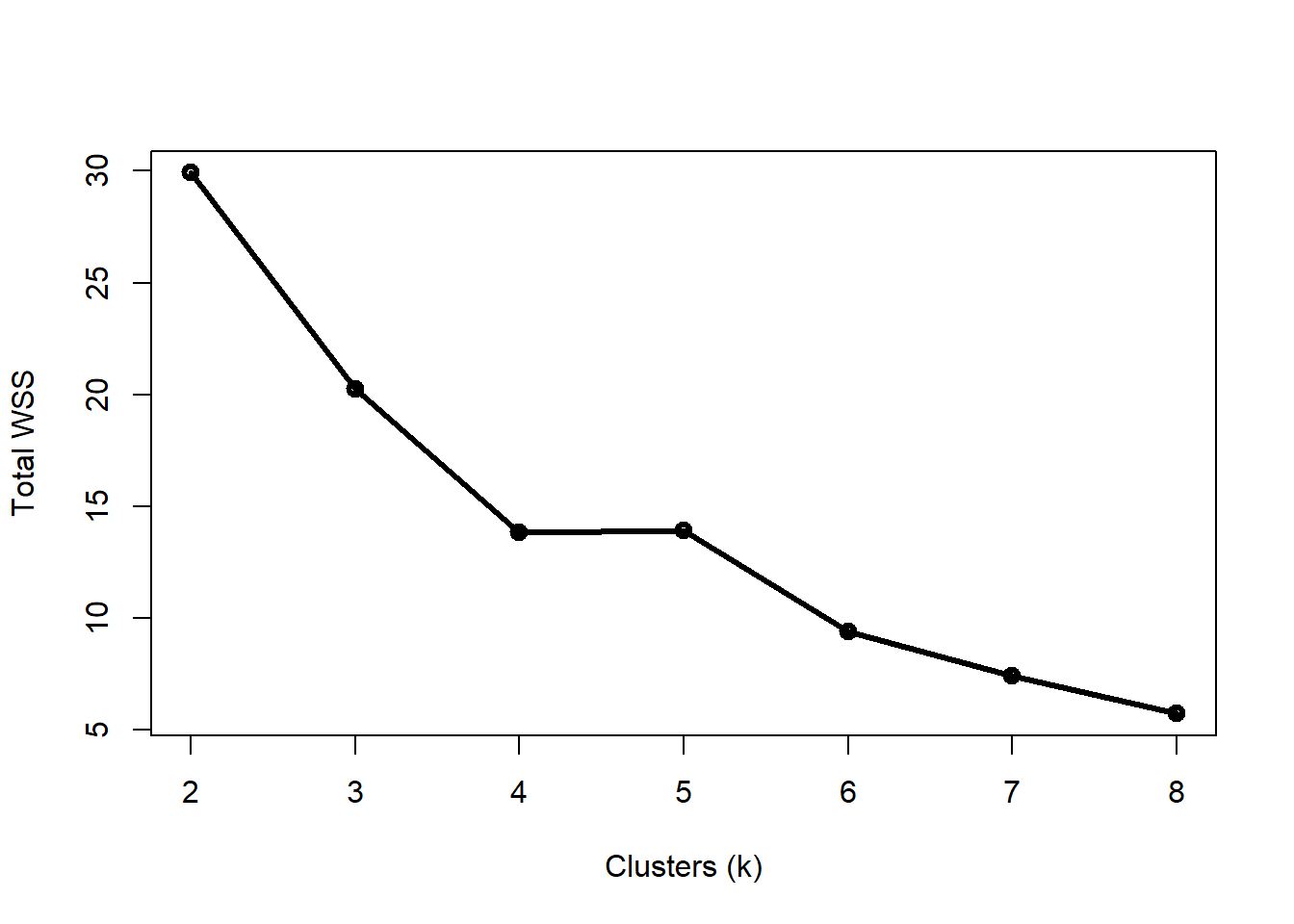
Four clusters appears to be the “elbow” of the curve, but this varied from run to run (try changing the random number seed and seeing if you get different results). Let’s use k = 4.
# assemble values needed for plots
## get clusters
dat$k4 <- k.list[[which(kvec == 4)]]$cluster
## coordinates of group centroids
km4 <- k.list[[which(kvec == 4)]]
dat$cenx4 <- km4$centers[dat$k4,1]
dat$ceny4 <- km4$centers[dat$k4,2]
## colors for each group
dat$col4 <- rainbow(4)[dat$k4]
# use PCA to define a reduced dimensional space
# (we'll cover PCA in detail later)
pr1 <- prcomp(dat[,1:12])
dat$x <- pr1$x[,1]
dat$y <- pr1$x[,2]
# make plot
par(mfrow=c(1,1))
plot(dat$x, dat$y, type="n",
xlab="PC 1(54%)", ylab="PC2 (19%)")
text(dat$x, jitter(dat$y, amount=0.1),
rownames(dat), col=dat$col4)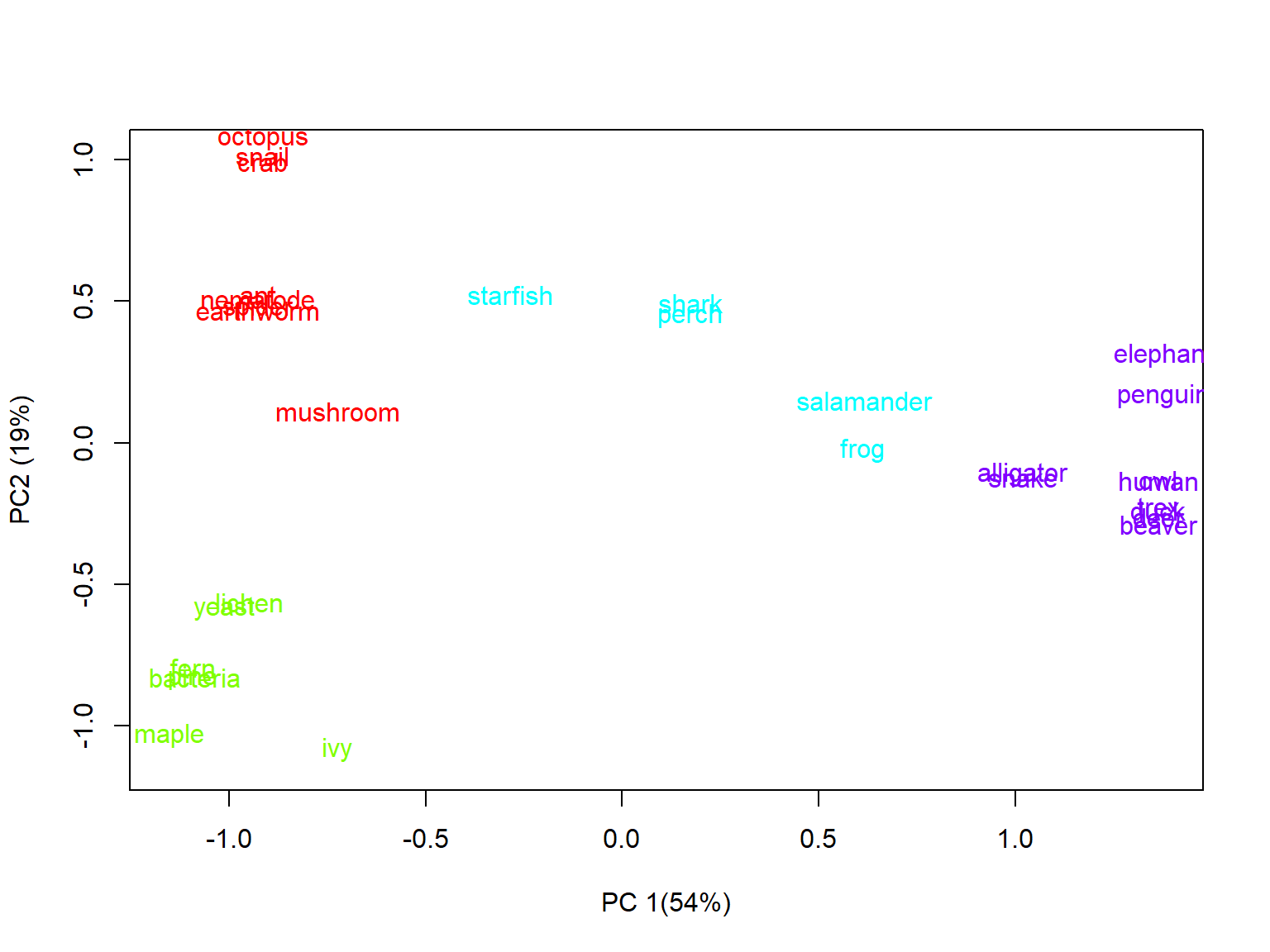
It’s a little hard to see some of the names, even with the jittering of the Y coordinates. How did the algorithm do? The groups appear to mostly make sense, but there are some oddities. For example:
- Elephants and penguins are more similar than either is to other mammals or birds, respectively (although they are in the same group).
- Salamanders and frogs were grouped with fish and echinoderms, despite being tetrapods.
- Mushrooms are clustered with the protostome invertebrates, despite being more closely related to yeast (which are grouped with the microbes and plants).
So, the results of the k-means clustering are mostly okay, but there is definitely plenty of room for improvement.
13.3.2 Hierarchical agglomerative clustering
One key disadvantage of k-means clustering is that it is not hierarchical: all groups are assumed to be homogenous, with no within-group structure or subgroups. In biological systems this is rarely the case. Many biological phenomena can be understood as hierarchical: for example, phylogeny and taxonomy. Hierarchical clustering can help discover, or at take advantage of, these relationships within your data.
There are many methods of hierarchical clustering, just as there were many methods of k-means clustering. One of the most common is Ward’s method (Ward 1963), which has many variations. The basic procedure is:
- Start with every sample separate (i.e., in its own cluster).
- Find a pair of clusters to combine that leads to the smallest increase in total within-cluster variance
- Repeat step 2 until a stopping point is reached (varies by method).
The within-cluster variance is an example of an objective function, which measures how effectively a statistical model represents the data. Different versions of Ward’s method use different objective functions. The most common is the Euclidean distance between cluster centroids. Squared Euclidean distance and other metrics are also seen in the literature.
The example below applies hierarchical clustering to the taxonomy dataset seen above. The base R function for hierarchical clustering is hclust(). The data are provided as a distance matrix rather than as raw values. We’ll use the vegdist() function from package vegan instead of the base R dist() function because it offers more distance metrics. Note that the code below assumes that you have the data file tax_example_2021-10-27.csv (here) in your R home directory.
set.seed(123)
in.name <- "tax_example_2021-10-27.csv"
dat <- read.csv(in.name, header=TRUE)
rownames(dat) <- dat$organism
dat$organism <- NULL
library(vegan)## Warning: package 'vegan' was built under R version 4.3.3## Loading required package: permute## Warning: package 'permute' was built under R version 4.3.3## Loading required package: lattice## This is vegan 2.6-6.1d1 <- vegdist(dat, method="euclidean")
d2 <- vegdist(dat) # default bray-curtis
h1 <- hclust(d1, method="ward.D")
plot(h1)
The results of hierarchical clustering are usually presented as a dendrogram. The word root dendro- means “tree”, which is a good way to think of a dendrogram. The branches show the relationship between the clusters. In the result above, pines and ferns form a cluster, as do maple and ivy. The “pine-fern” and “maple-ivy” clusters together form a bigger cluster.
The clustering based on Bray-Curtis distances is slightly different:
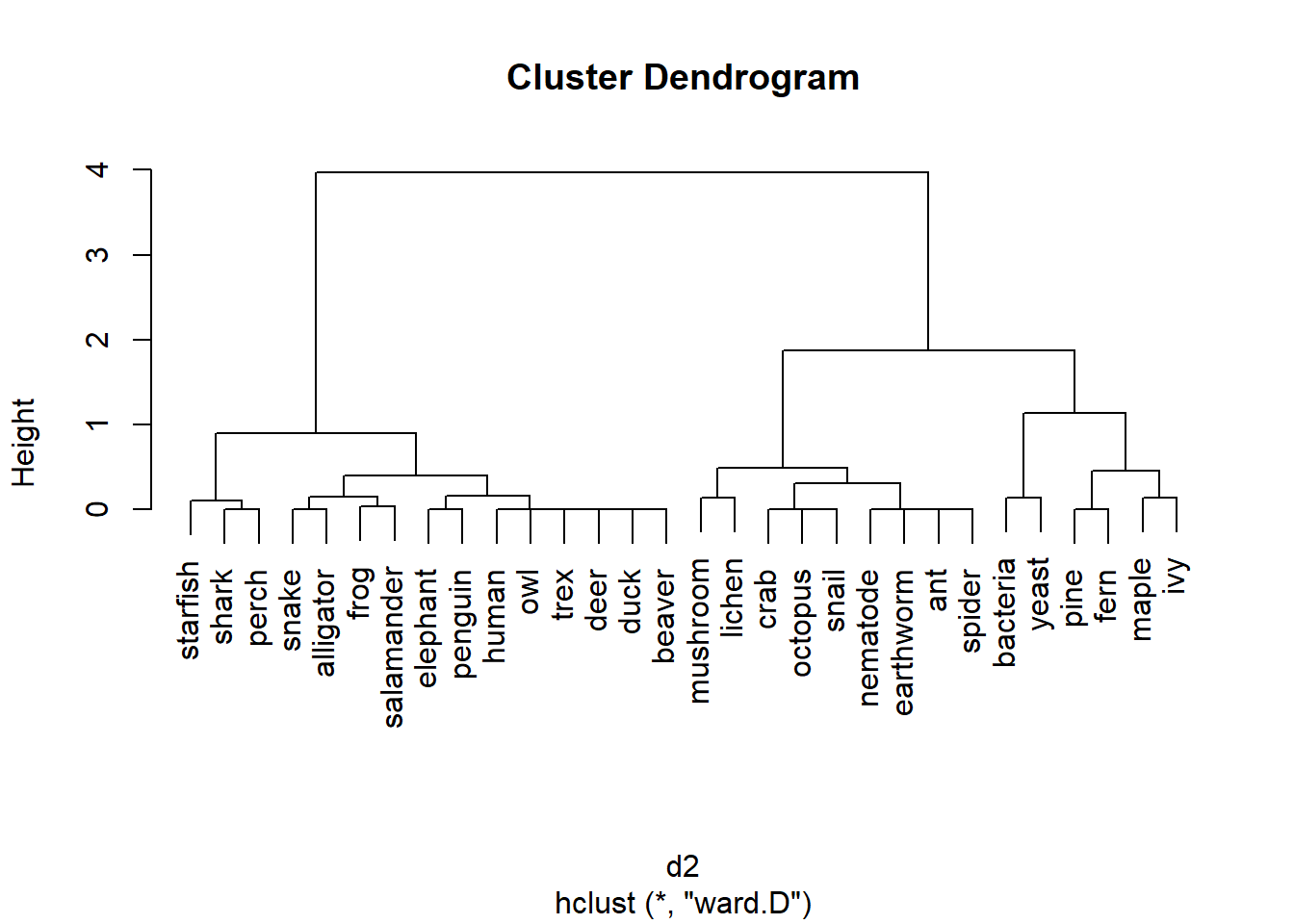
The results using the Euclidean and Bray-Curtis distance metrics are similar, but both dendrograms make some “interesting” choices. For example, one would expect the most basal (toward the root of the tree) division between animals and non-animals, or between prokaryotes and eukaryotes. Is that the case?
Not at all. The method clustered the taxa in a way that doesn’t match their real-life phylogenetic relationships. This is partly because of the characteristics that were used (a very vertebrate animal-centric set!). This also illustrates the difference between taxonomy, which seeks to combine organisms by shared characteristics; and phylogeny, which results from how lineages divide over time.
13.4 Analyzing dissimilarity
A metric like the Bray-Curtis or Euclidean metric can quantify how different samples are from each other in terms of many variables simultaneously. The natural next question to ask is, “So what?”. Just as we can compare means between groups, or measure whether two variables are correlated, we can compare distances between groups or test whether two sets of distances are correlated. This document demonstrates some ways to use distance metrics to generalize common univariate and bivariate tests to patterns in higher dimensions.
13.4.1 Mantel tests: distance vs. distance
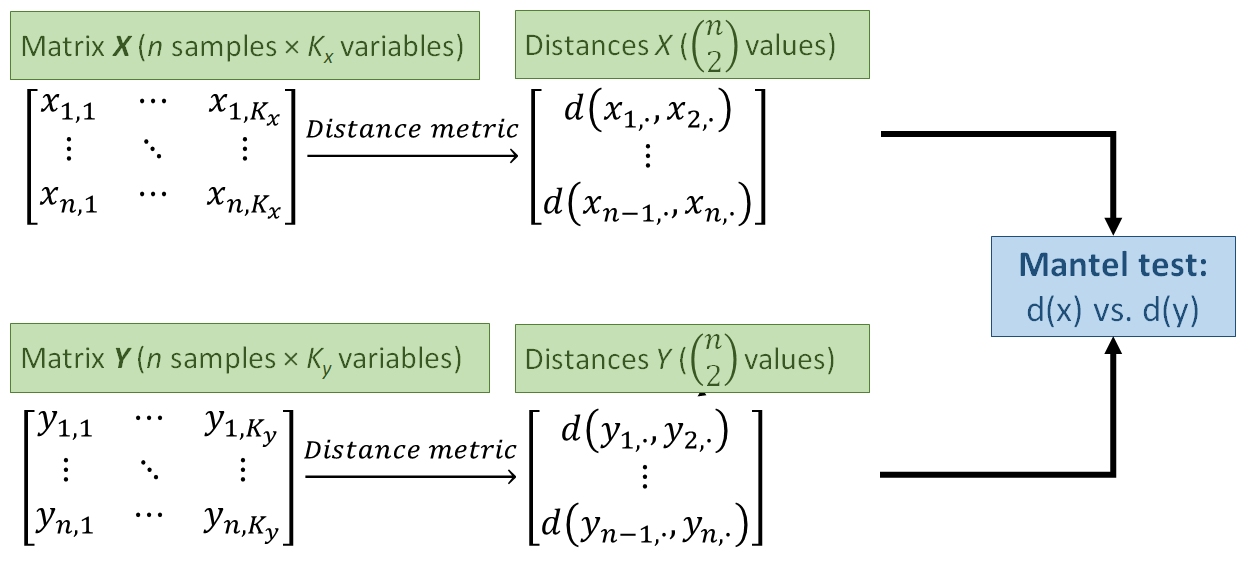
One way to use distance metrics in a biological investigation is to calculate different distances between samples using different sets of variables, and then see if those distances are related. For example, an ecologist might calculate distances between sites using plant cover data, and a separate set of distances using soil chemistry data. She would then have one distance metric describing differences between the sites in terms of their plant cover, and a second distance metric describing differences between the sites in terms of their soil characteristics. A natural question to ask then is, “is distance in terms of plant cover related to distance in terms of soil chemistry?”. In other words, “do sites that are more similar in terms of their soil chemistry tend to be more similar in terms of their plant cover?”
Answering these questions is tantamount to calculating a correlation coefficient between two vectors of distance metrics. This procedure is called a Mantel test (Mantel 1967). The Mantel correlation coefficient r answers the question, “How is variation in one set of variables related to variation in another set of variables?”.
The example below uses the iris dataset to test whether variation in petal morphology is related to variation in sepal morphology. Note that while the Euclidean distance metric is used here because data are known to be multivariate normal, the Bray-Curtis or other metrics may be more appropriate in other situations.
# get sepal and petal variables from iris
x1 <- iris[,grep("Sepal", names(iris))]
x2 <- iris[,grep("Petal", names(iris))]
# calculate distance metrics
library(vegan)
d1 <- vegdist(x1, method="euclidean")
d2 <- vegdist(x2, method="euclidean")
d3 <- vegdist(x1) # vegdist() default metric = Bray-Curtis
d4 <- vegdist(x2)
# Mantel test on Euclidean distances
mantel(d1, d2)##
## Mantel statistic based on Pearson's product-moment correlation
##
## Call:
## mantel(xdis = d1, ydis = d2)
##
## Mantel statistic r: 0.7326
## Significance: 0.001
##
## Upper quantiles of permutations (null model):
## 90% 95% 97.5% 99%
## 0.0242 0.0330 0.0409 0.0490
## Permutation: free
## Number of permutations: 999The Mantel statistic r is exactly the same as the Pearson product moment correlation r between the two sets of distance metrics (verify this with the command cor(d1, d2)). The significance of the Mantel r is usually calculated by a permutation test instead of the more conventional methods . A permutation test for significance works by rearranging, or permuting, the observations many times and comparing a statistic (r) to the distribution of the statistic across the permutations. The P-value is calculated as the proportion of permutations that had a statistic with a magnitude at least as great as the original statistic. In the example above, P = 0.001 because at most 1 out of 999 permutations had an r \(\ge\) 0.7326.
The function below will replicate the permutation test done for the Mantel test above. This function is provided for didactic purposes only. You should use the methods built into R and vegan instead. But, studying the code below can help you understand how a permutation test works.
simple.ptest <- function(dm1, dm2, n=999){
r <- cor(dm1, dm2)
dn <- length(dm1)
rvec <- numeric(dn)
for(i in 1:dn){
i1 <- d1[sample(1:dn, replace=FALSE)]
i2 <- d2[sample(1:dn, replace=FALSE)]
rvec[i] <- cor(i1, i2)
}
res <- length(which(rvec >= r))/dn
return(res)
}
simple.ptest(d1, d2, 999)## [1] 0Mantel tests are usually reported by their numerical outputs, but you can plot the results if the test is central to your presentation. The simplest way is to plot the distance metrics on a scatterplot. The example below uses partial transparency to better show the overlapping points. A diagonal red line shows where the two dissimilarities are equal.
plot(d1, d2, pch=16, col="#00000020",
xlab="Sepal dissimilarity (Eucl.)",
ylab="Petal dissimilarity (Eucl.)")
segments(0, 0, max(d1), max(d2),
lwd=3, col="red")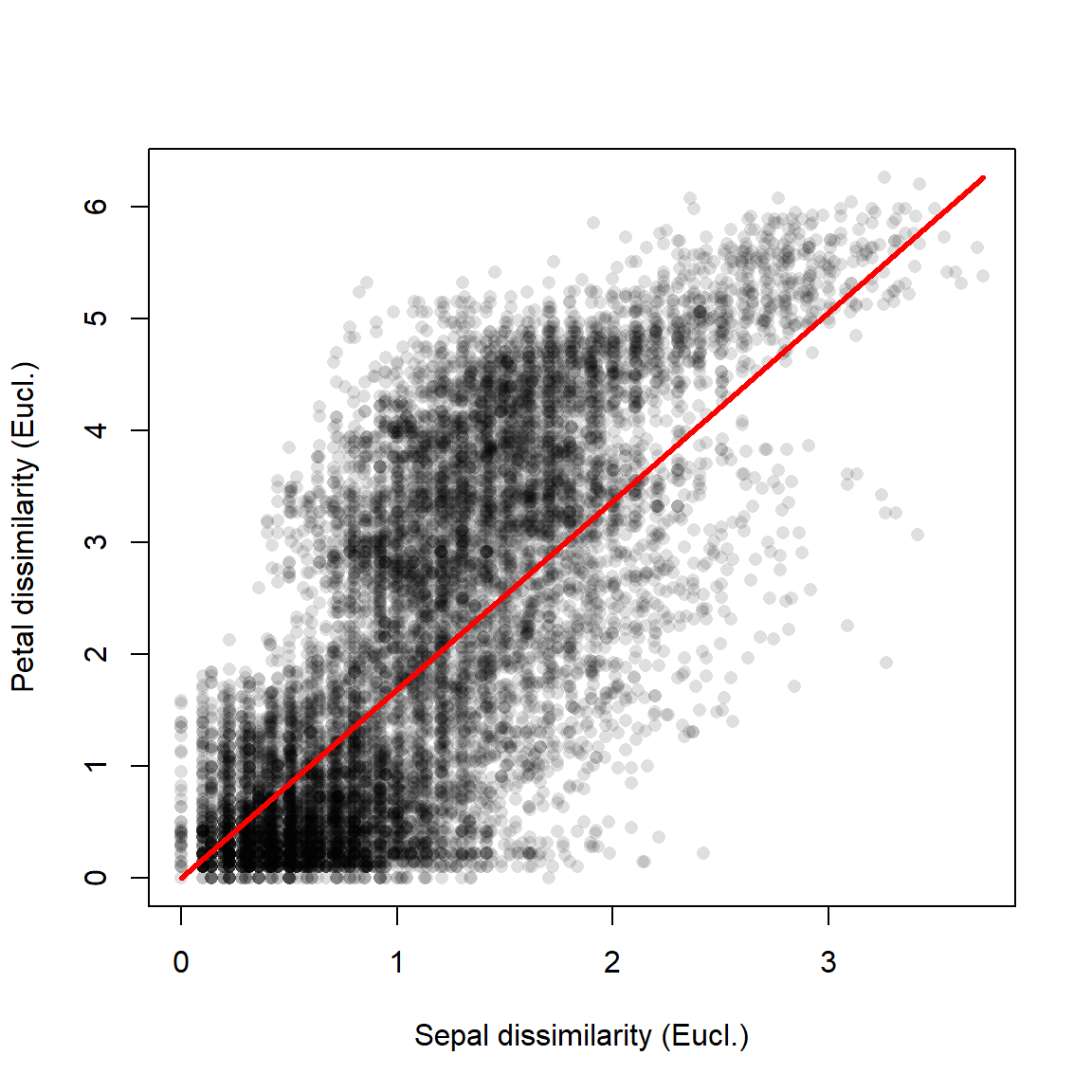
The figure shows what the Mantel r statistic already indicated: that flowers with similar sepal morphology tend to have similar petal morphology.
Just for fun, the figure below visualizes the Mantel correlation based on the Euclidean (left) and Bray-Curtis (right) distances.
d3 <- vegdist(x1) # default Bray-Curtis
d4 <- vegdist(x2)
mantel(d3, d4)
##
## Mantel statistic based on Pearson's product-moment correlation
##
## Call:
## mantel(xdis = d3, ydis = d4)
##
## Mantel statistic r: 0.6552
## Significance: 0.001
##
## Upper quantiles of permutations (null model):
## 90% 95% 97.5% 99%
## 0.0260 0.0365 0.0459 0.0578
## Permutation: free
## Number of permutations: 999
par(mfrow=c(1,2), mar=c(5.1, 5.1, 1.1, 1.1),
bty="n", lend=1, las=1,
cex.axis=1.3, cex.lab=1.3)
plot(d1, d2, pch=16, col="#00000020",
xlab="Sepal dissimilarity (Euclidean)",
ylab="Petal dissimilarity (Euclidean)")
segments(0, 0, max(d1), max(d2),
lwd=3, col="red")
plot(d3, d4, pch=16, col="#00000020",
xlab="Sepal dissimilarity (Bray-Curtis)",
ylab="Petal dissimilarity (Bray-Curtis)")
segments(0, 0, max(d3), max(d4),
lwd=3, col="red")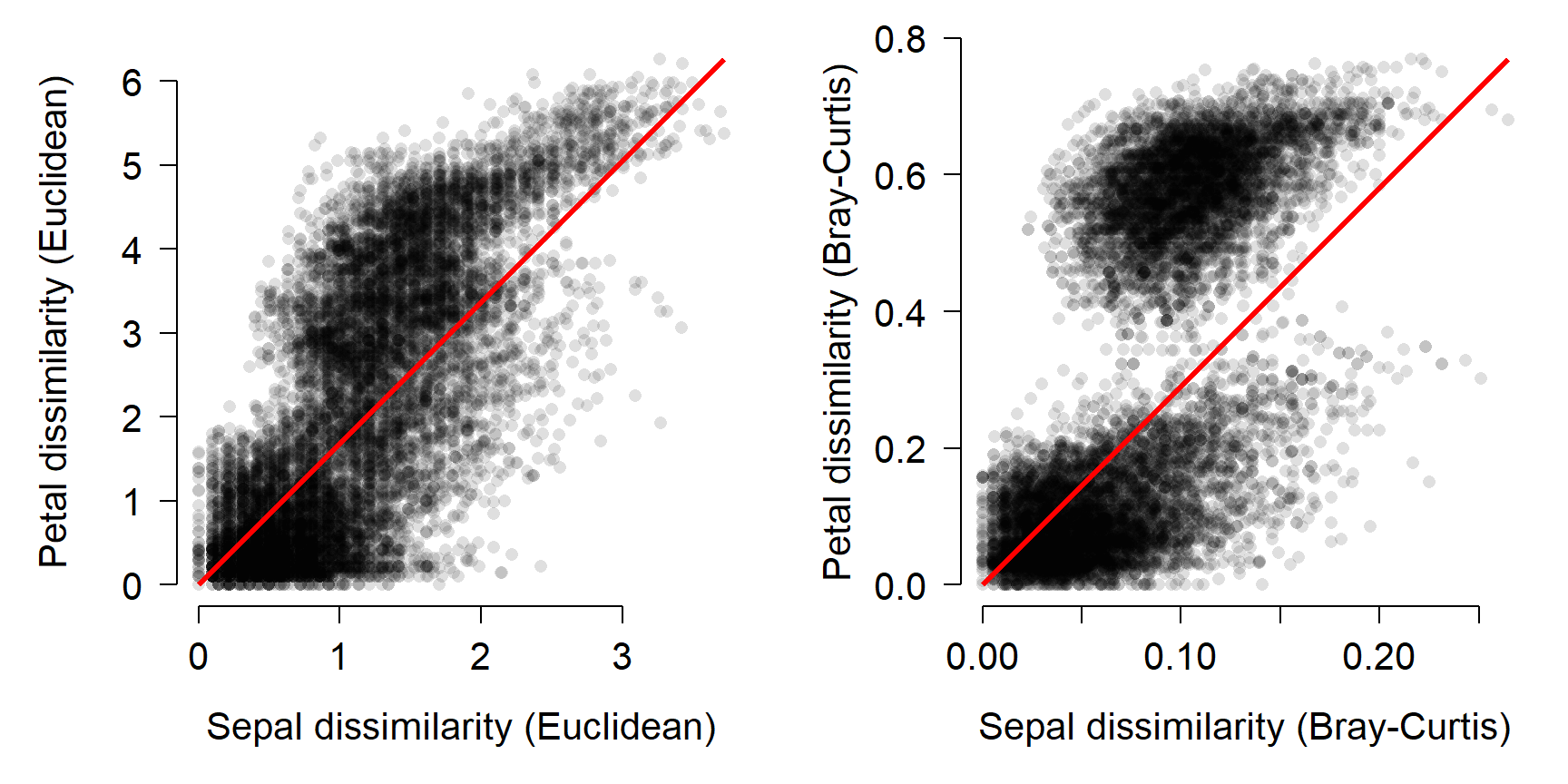
Interestingly, the Bray-Curtis distances seemed to fall into two clusters in terms of the petal dissimilarity. That probably has something to do with the difference between I. setosa and the other species, but I haven’t investigated it.
The Mantel test can also be performed with correlation coefficients other than the linear correlation coefficient. This makes sense if the correlation appears nonlinear. For example, if one dissimilarity metric increases consistently with the other dissimilarity metric, but not in a straight line. The most common alternative is the Spearman’s rank correlation coefficient \(\rho\) (“rho”).
##
## Mantel statistic based on Spearman's rank correlation rho
##
## Call:
## mantel(xdis = d1, ydis = d2, method = "spearman")
##
## Mantel statistic r: 0.7258
## Significance: 0.001
##
## Upper quantiles of permutations (null model):
## 90% 95% 97.5% 99%
## 0.0197 0.0253 0.0298 0.0362
## Permutation: free
## Number of permutations: 999##
## Mantel statistic based on Spearman's rank correlation rho
##
## Call:
## mantel(xdis = d3, ydis = d4, method = "spearman")
##
## Mantel statistic r: 0.69
## Significance: 0.001
##
## Upper quantiles of permutations (null model):
## 90% 95% 97.5% 99%
## 0.0247 0.0331 0.0392 0.0540
## Permutation: free
## Number of permutations: 999Changing from a linear to nonlinear correlation coefficient slightly decreased the Mantel correlation for the Euclidean distances (0.7326 to 0.7258), and slightly increased the correlation for the Bray-Curtis distances (0.6552 to 0.69). Examine the figure above and see if you can work out why this is.
The figure below shows the two sets of distances with two lines: a straight line to represent the linear correlation r and a spline curve to represent the nonlinear correlation \(\rho\).
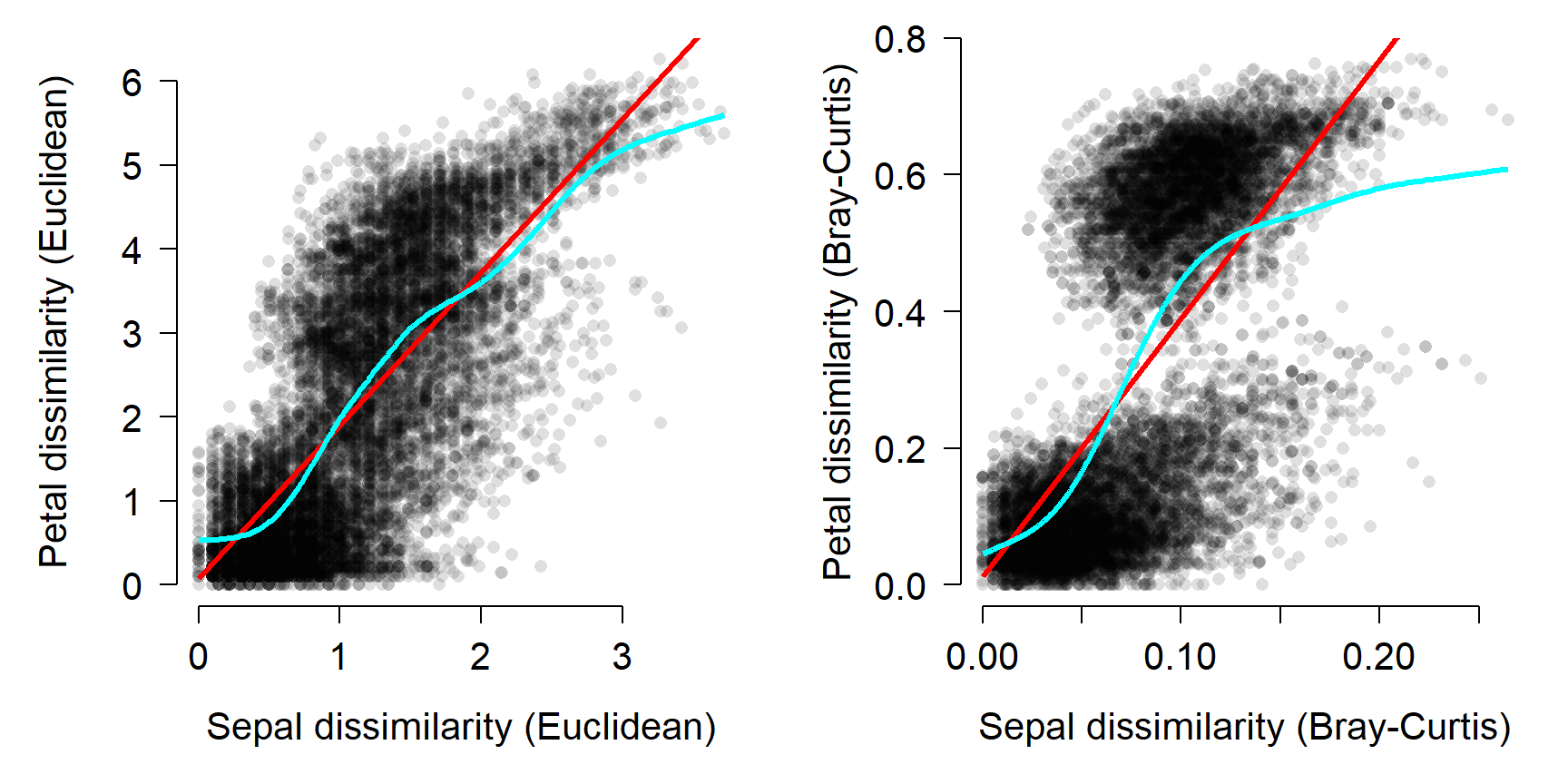
13.4.2 Comparing dissimilarity between groups
Just as the Mantel test generalizes the idea of correlation from “one variable vs. one variable” to “many variables vs. many variables”, other techniques generalize the idea of group differences from “difference in means between groups” to “differences in centroids between groups”. This section demonstrates three common tests for multivariate differences between groups.
13.4.2.1 Analysis of similarity (ANOSIM): distances between groups
The analysis of similarities (ANOSIM) is a nonparametric, ANOVA-like test that tests whether similarity between groups is greater than or equal to the similarity within groups (Clarke 1993). This is analogous to how ANOVA tests whether the difference in means (i.e., variance) between groups is greater than or equal to the variance within groups. What makes the test nonparametric is that it operates on the rank-transformed distance matrix rather than on the actual distance metrics.
The vegan function anosim() is used for ANOSIM. The function takes the original data matrix, a grouping variable, and can use any distance metric available in vegan::vegdist(). The example below uses the Euclidean metric because the data are known to be multivariate normal; you may need to use the Bray-Curtis or another metric with your own data.
##
## Call:
## anosim(x = iris[, 1:4], grouping = iris$Species, distance = "euclidean")
## Dissimilarity: euclidean
##
## ANOSIM statistic R: 0.8794
## Significance: 0.001
##
## Permutation: free
## Number of permutations: 999Like the Mantel test, ANOSIM estimates a P-value by permutation. In this case, the permutation is of group membership. The underlying idea is that if there are no differences between groups (i.e., if the null hypothesis were true), then group membership is irrelevant and changing group memberships should not affect any test statistics. The ANOSIM statistic R expresses the relationship between the difference in mean ranks between groups (\(mr_{between}\)) and the within groups (\(mr_{within}\)).
\[R=\frac{mr_{between}-mr_{within}}{\frac{1}{4}n(n-1)}\]
The denominator scales the difference in mean ranks from -1 to 1. R = 0 means that grouping is unrelated to differences in mean ranks; greater R values indicate that differences between groups are greater than differences within groups; smaller R values indicate the reverse. The R value in our test above suggests that about 87.9% of the variation in the rank order of the distance matrix can be attributed to differences between species of Iris.
13.4.2.2 MANOVA and PERMANOVA: distances between centroids
Multivariate analysis of variance (MANOVA) is an extension of ANOVA with multiple response variables. The underlying theory and matrix algebra is very similar to ANOVA, and so many of the same assumptions apply (just in many dimensions instead of one). For that reason, MANOVA is often not appropriate for real biological data without careful experimental design and exploratory data analysis to confirm that the test’s assumptions are met.
Y <- as.matrix(iris[,1:4])
mod1 <- manova(Y~iris$Species)
# (M)ANOVA table
summary(mod1, test="Pillai")## Df Pillai approx F num Df den Df Pr(>F)
## iris$Species 2 1.1919 53.466 8 290 < 2.2e-16 ***
## Residuals 147
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1## Sepal.Length Sepal.Width Petal.Length Petal.Width
## (Intercept) 5.006 3.428 1.462 0.246
## iris$Speciesversicolor 0.930 -0.658 2.798 1.080
## iris$Speciesvirginica 1.582 -0.454 4.090 1.780Permutational analysis of variance (PERMANOVA) is a nonparametric version of MANOVA (Anderson 2001). It is nonparametric because it uses permutation of group membership to determine statistical significance instead of calculating an F statistic based on probability theory. As of 2022, most common R function for PERMANOVA is adonis2() from the vegan package.
## Permutation test for adonis under reduced model
## Terms added sequentially (first to last)
## Permutation: free
## Number of permutations: 999
##
## adonis2(formula = iris[, 1:4] ~ iris$Species, method = "euclidean")
## Df SumOfSqs R2 F Pr(>F)
## iris$Species 2 592.07 0.86894 487.33 0.001 ***
## Residual 147 89.30 0.13106
## Total 149 681.37 1.00000
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 113.4.2.3 MRPP: differences in location
Multiple response permutation procedures (MRPP) is a permutational test for location that is very similar to ANOSIM (McCune et al. 2002). The practical difference between MRPP and ANOSIM is that MRPP is typically used on coordinates within an ordination space (usually NMDS), while ANOSIM is usually used with all variables (i.e., on the original data).
In this example, we first fit an NMDS ordination to the iris data, then use MRPP to test whether the 3 species differ from each other. NMDS will be described in detail in its own page, but for now just understand that proximity in NMDS coordinates represents proximity in terms of the original variables. The question addressed by the MRPP is basically the same as asking whether the 3 clouds of points in the ordination space overlap or not.
## Run 0 stress 0.03775523
## Run 1 stress 0.0471371
## Run 2 stress 0.04355784
## Run 3 stress 0.03775521
## ... New best solution
## ... Procrustes: rmse 8.391196e-06 max resid 8.977599e-05
## ... Similar to previous best
## Run 4 stress 0.03775524
## ... Procrustes: rmse 8.500839e-06 max resid 3.692894e-05
## ... Similar to previous best
## Run 5 stress 0.04355786
## Run 6 stress 0.04367523
## Run 7 stress 0.03775526
## ... Procrustes: rmse 1.432606e-05 max resid 6.377157e-05
## ... Similar to previous best
## Run 8 stress 0.04367518
## Run 9 stress 0.03775521
## ... New best solution
## ... Procrustes: rmse 2.883636e-06 max resid 1.522455e-05
## ... Similar to previous best
## Run 10 stress 0.04367546
## Run 11 stress 0.03775521
## ... Procrustes: rmse 3.296088e-06 max resid 1.587904e-05
## ... Similar to previous best
## Run 12 stress 0.03775521
## ... Procrustes: rmse 1.918317e-06 max resid 9.027271e-06
## ... Similar to previous best
## Run 13 stress 0.05326437
## Run 14 stress 0.03775525
## ... Procrustes: rmse 1.432105e-05 max resid 6.189916e-05
## ... Similar to previous best
## Run 15 stress 0.04355785
## Run 16 stress 0.05289953
## Run 17 stress 0.03775523
## ... Procrustes: rmse 9.653584e-06 max resid 4.183544e-05
## ... Similar to previous best
## Run 18 stress 0.03775521
## ... Procrustes: rmse 2.537687e-06 max resid 1.271634e-05
## ... Similar to previous best
## Run 19 stress 0.03775525
## ... Procrustes: rmse 1.397257e-05 max resid 6.050249e-05
## ... Similar to previous best
## Run 20 stress 0.05537383
## *** Best solution repeated 7 times# extract scores (coordinates)
nx <- scores(n1)$sites[,1]
ny <- scores(n1)$sites[,2]
# set up some colors for the plot
cols <- rainbow(3)
use.cols <- cols[as.numeric(iris$Species)]
# make the plot
plot(nx, ny, pch=16, col=use.cols,
cex=1.5,
xlab="NMDS 1", ylab="NMDS 2")
legend("top", legend=unique(iris$Species),
pch=16, cex=1.5, col=cols)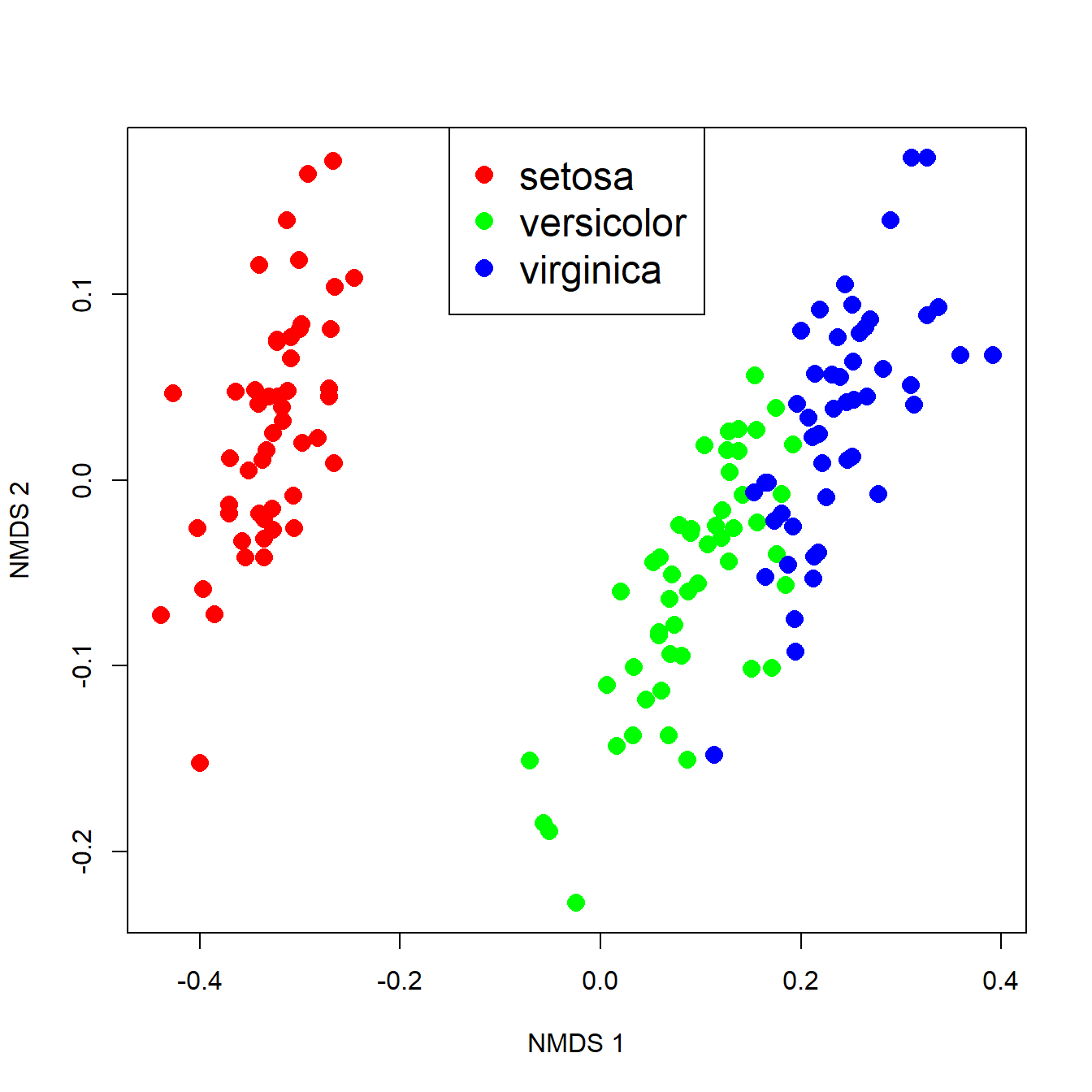
The figure suggests that there is good separation between at least I. setosa and the other species, and likely separation between I. versicolor and I. virginica. The MRPP will test whether or not the clouds of points overlap.
##
## Call:
## mrpp(dat = scores(n1)$sites, grouping = iris$Species)
##
## Dissimilarity index: euclidean
## Weights for groups: n
##
## Class means and counts:
##
## setosa versicolor virginica
## delta 0.09269 0.1086 0.1035
## n 50 50 50
##
## Chance corrected within-group agreement A: 0.6635
## Based on observed delta 0.1016 and expected delta 0.3018
##
## Significance of delta: 0.001
## Permutation: free
## Number of permutations: 999The test statistics are delta (\(\delta\)), the weighted mean within-group distance; and A, the chance-corrected within-group agreement or agreement statistic.
- The \(\delta\) value for each group with expresses how homogenous the group is.
- When \(\delta\) = 0, all members of a group are identical (i.e., have identical location in the NMDS space).
- The mean of the group-level \(\delta\) is reported as the “observed delta”.
- The agreement statistic A scales \(\delta\) to the within-group homogeneity expected by chance if group membership was unrelated to location (expected delta in the output above).
- Greater values of A indicate higher agreement within groups.
- A ranges from 0 (heterogeneity within groups equal to heterogeneity expected by chance) to 1 (items within groups identical).
- In practice, values of A > 0.3 are rather high.
The significance of the MRPP is calculated by permutation, just as in the Mantel test or ANOSIM. As with any statistical test, the P-value is sensitive to not only the effect size, but also the sample size. Large sample sizes can make tiny differences appear statistically significant, so it is up to you as a biologist to interpret the output of the test.
13.5 Ordination
In the last section we saw an application of ordination: representing high-dimensional relationships between objects in a 2-d space. This is done in such a way as to represent important patterns in the data in few enough dimensions for our 3-d brains to handle.
Ordination is literally ordering observations along two or more axes. That is, coming up with a new coordinate system that shows relationships between observations. How that ordering is done varies wildly among techniques. One broad class of techniques, collectively called eigenvector based methods, use the power of linear algebra to place the data into a new coordinate system that better captures the patterns in the data. The other class uses Monte Carlo sampling to find arrangements of samples that retain the important patterns in reduced dimension space.
No matter how they work, all ordination methods have the same goal: representing patterns found in many dimensions in fewer dimensions. For this course our focus will be on interpretation rather than calculation. The applications of ordination overlap with those of the multivariate techniques that we have already seen.
- Cluster identification: observations that are closer to each other in the ordination space are more similar to each other
- Dimension reduction: the axes of an ordination are estimates of synthetic variables that combine information about many variables at once.
13.5.1 Principal components analysis (PCA)
13.5.1.1 PCA intro
Principal components analysis (PCA) is a method for extracting synthetic gradients from a multivariate dataset that capture most of the variation in that dataset. These gradients are calculated by finding linear combinations of the variables that minimize sums of squared deviations from the gradient. This means that PCA has a lot in common with linear regression, and many of the same assumptions apply. If you’ve never heard of principal components analysis or ordination, it might be worth watching a video that explains and shows the basic ideas. Here is one that only takes 5 minutes and has a nice theme song (accessed 2022-08-15).
Imagine a dataset with 2 variables, x and y. You could capture and display all the information about this dataset in a 2-d scatterplot, by simply plotting y vs. x. Likewise, you could capture and display all of the information about a 3-dimensional dataset with a 3-d plot. For 4 or more dimensions, a true scatterplot can’t be rendered sensibly or even understood by our pathetic meat-based brains.
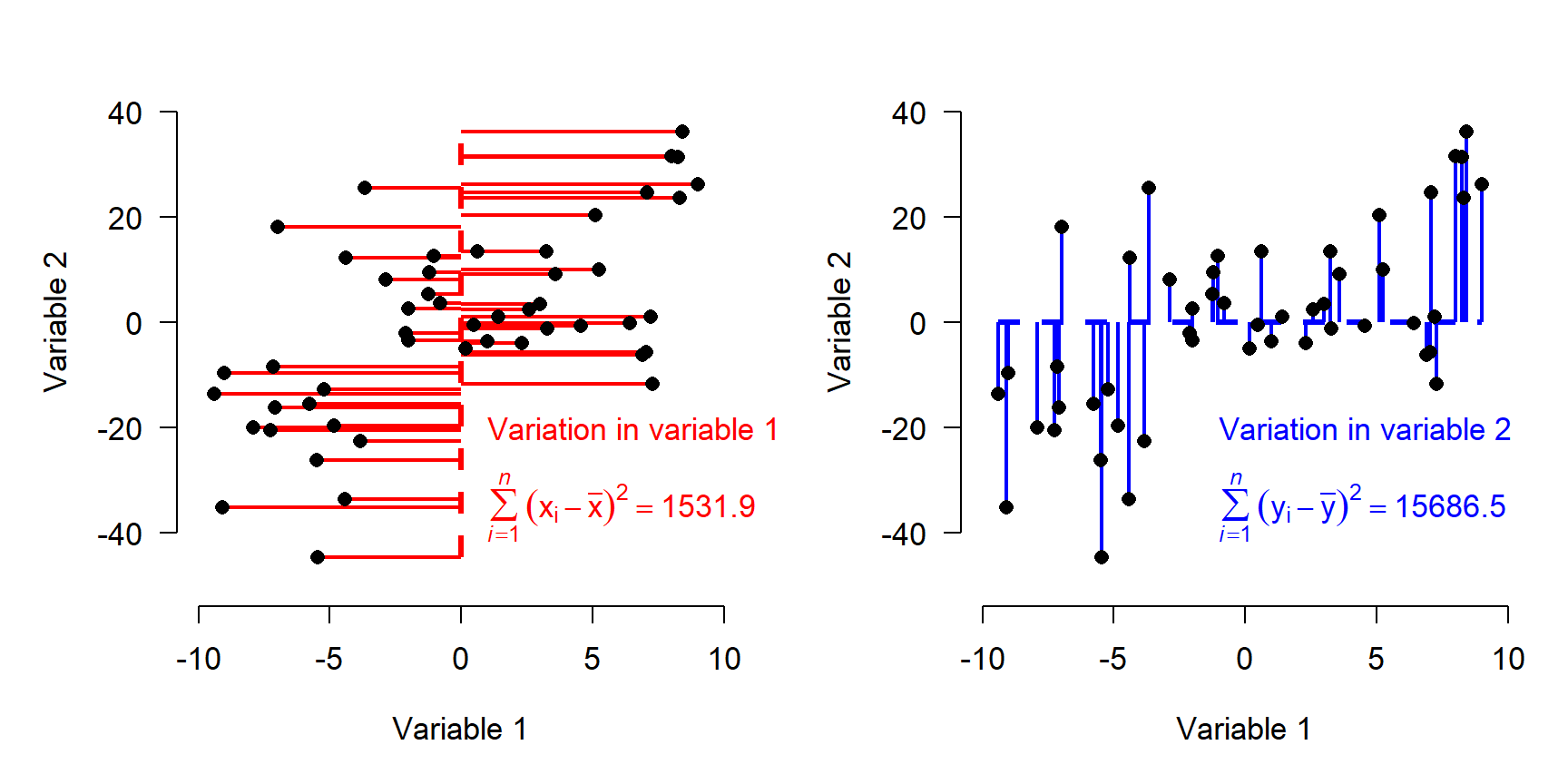
One way to describe the variation in the dataset above is to think about how the samples vary along each axis. The figure below shows how the variation among samples can be broken down into the variation in Variable 1 and the variation in Variable 2. When we say “variation in variable 1”, we mean “deviation between the values of variable 1 and the mean of variable 1”. That is what is shown in the figure below.
- Each point, or sample, has a Variable 1 coordinate and a Variable 2 coordinate.
- Each point’s value for Variable 1 can be thought of as the difference between that value and the mean of Variable 1.
- Likewise, each point’s value for Variable 2 can be thought of as the difference between that value and the mean of Variable 2.
- The position of each point can thus be reframed as its deviation with respect to the Variable 1, and its deviation with respect to Variable 2. This reframing is the same as centering each variable (i.e., subtracting the mean).
- The total variance among the samples is equal to the variance with respect to Variable 1 plus the variance with respect to Variable 2.
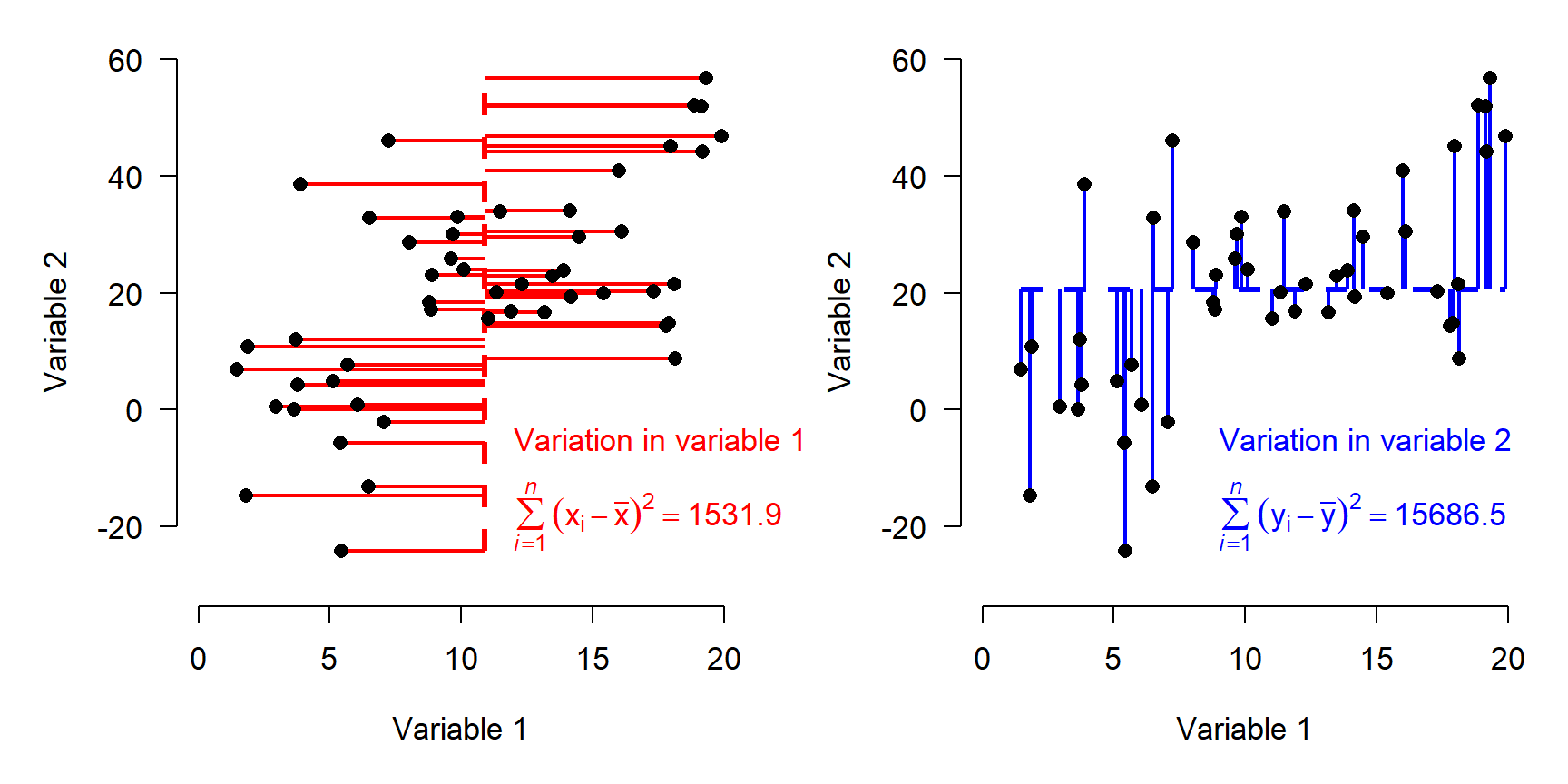
The figure above shows how the total variation in the dataset is split up (“partitioned”) into variation in Variable 1 and variation in Variable 2.
Describing each observation as its deviation from the mean of each variable has the effect of centering the points at the origin. Notice that the variation, expressed as sums of squared deviations, is unchanged.
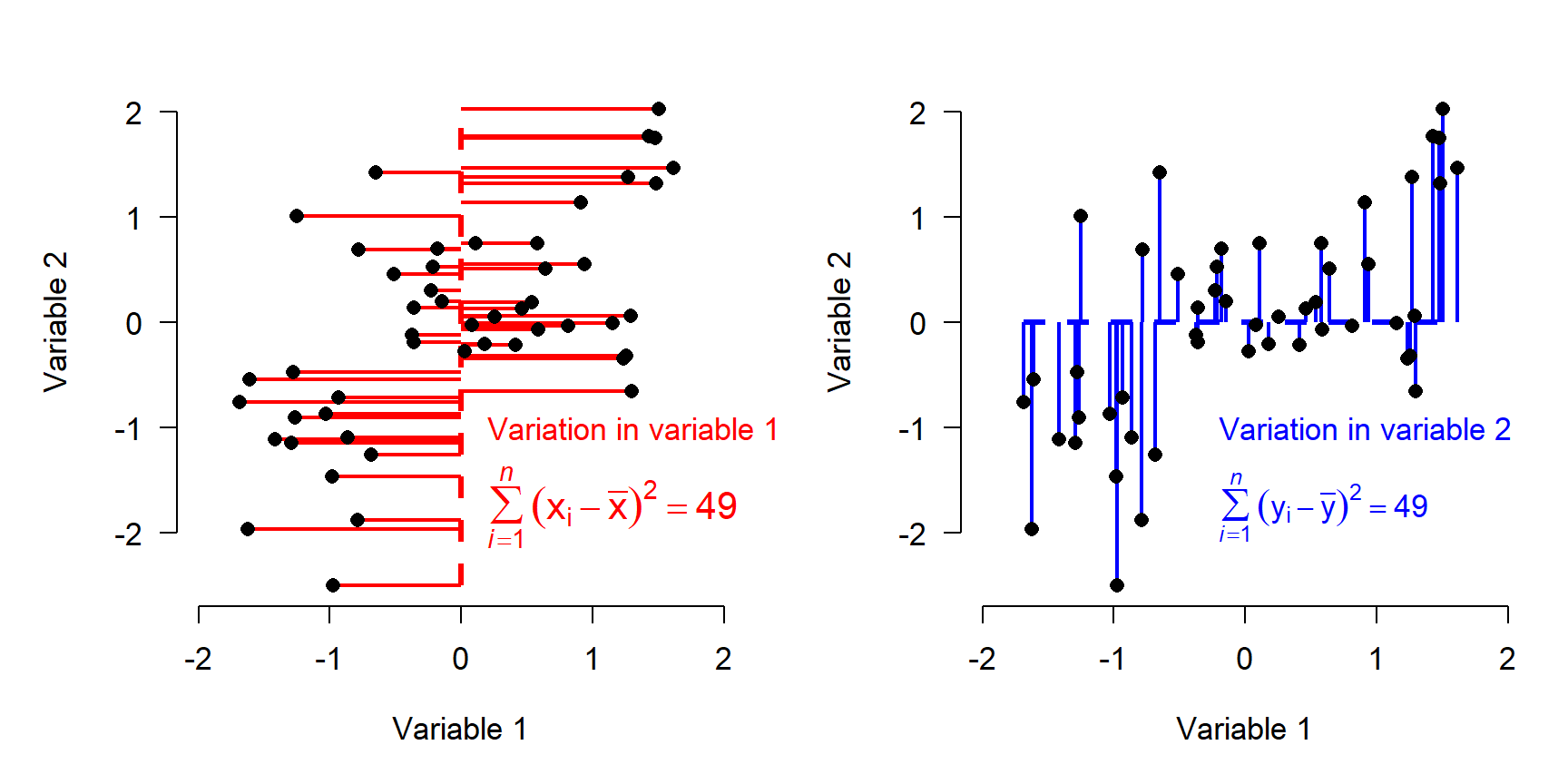
If variables have different ranges, it is a good idea to scale them as well as center them (aka: standardizing or Z-scaling). This means that the original values are converted to Z-scores by subtracting the mean and dividing by the SD. Trying to use PCA or other eigenvector-based methods without standardizing variables will distort the results. Standardization puts variation along any axis on equal footing.
The figure below shows the data as deviations from variable means after standardization. Note that the sums of squares are equal in both directions now.
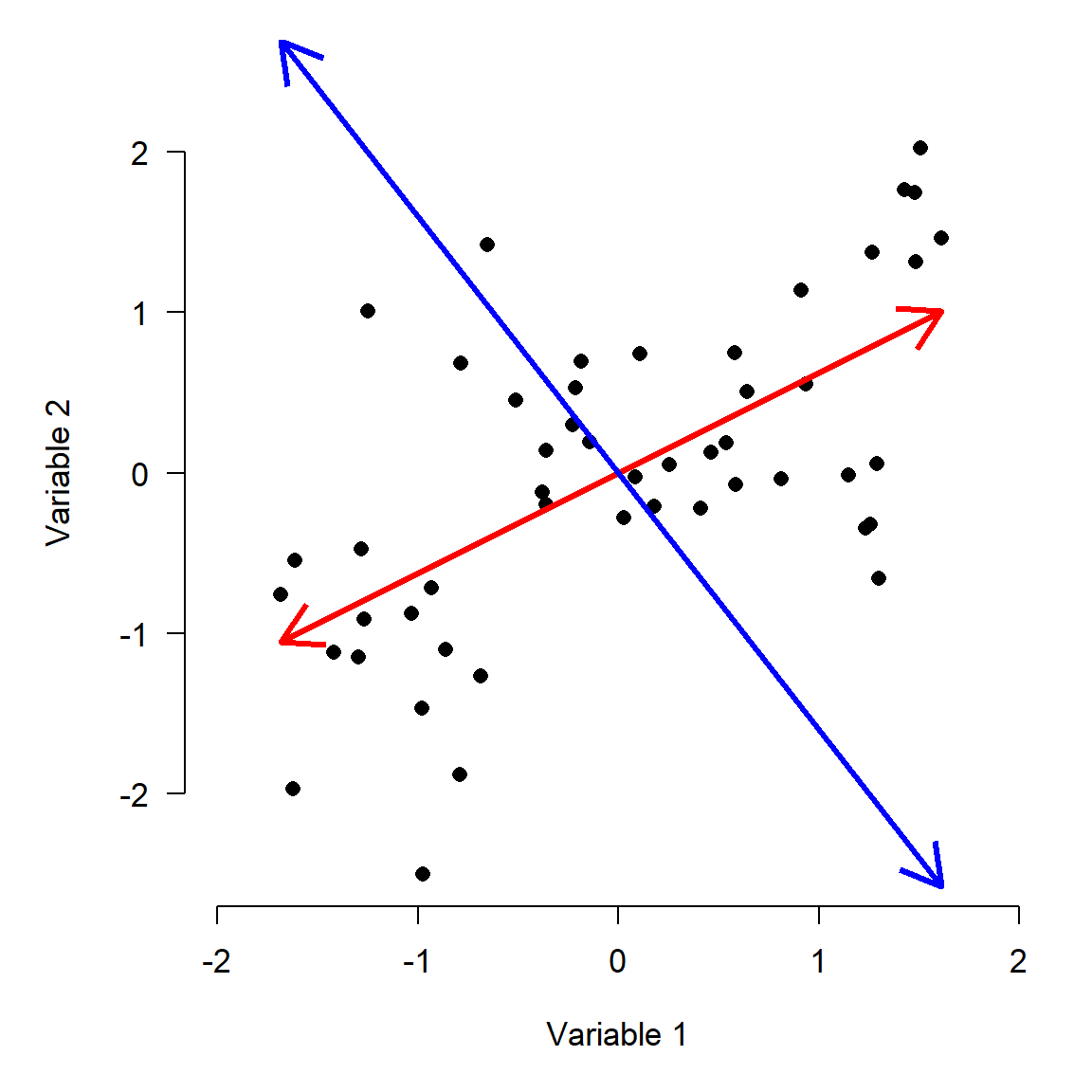
 If our goal is to describe variation in the data as succinctly as possible, then using Variable 1 and Variable 2 as axes might not be the best approach. Notice that most of the variation in the points doesn’t line up exactly with either of the variables, but along the red arrow shown below. The rest of the variation is along the direction perpendicular to the red arrow, illustrated by the blue arrow. (Note that the arrows may only appear perpendicular if the plot is precisely square).
If our goal is to describe variation in the data as succinctly as possible, then using Variable 1 and Variable 2 as axes might not be the best approach. Notice that most of the variation in the points doesn’t line up exactly with either of the variables, but along the red arrow shown below. The rest of the variation is along the direction perpendicular to the red arrow, illustrated by the blue arrow. (Note that the arrows may only appear perpendicular if the plot is precisely square).
The red arrow is a vector that contains information about both Variable 1 and Variable 2. It is tricky, but not too hard, to calculate each observation’s deviations from the mean of that vector (left panel below). We can also calculate the deviations along a perpendicular vector, because even after describing the variation in the “red” direction, there is still some variation in the “blue” direction (right panel).
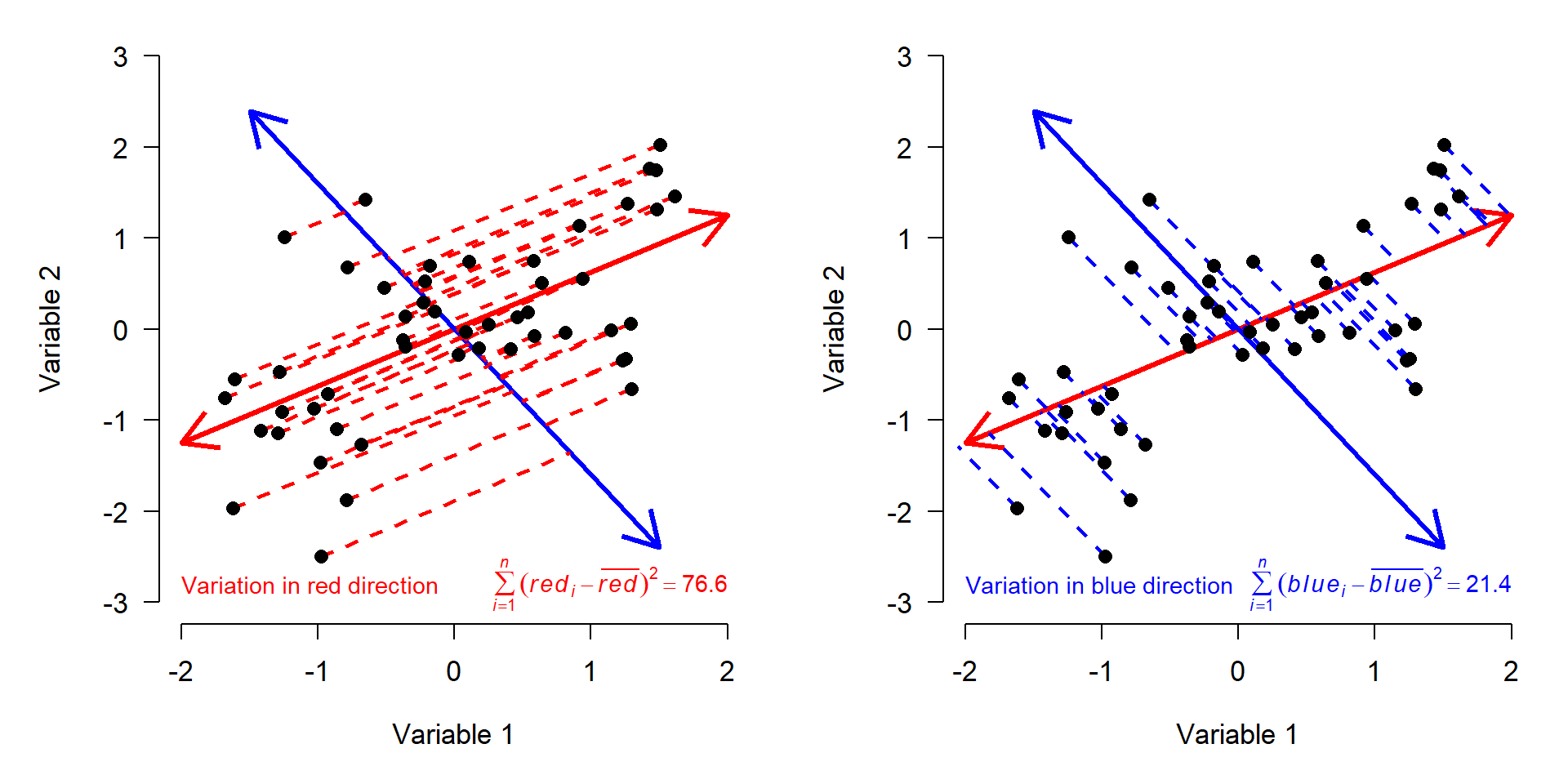
We know that the variation on the red and blue axes is the same as the variation on the X and Y axes, because the sums of squares are the same. The red and blue axes are just different ways of orienting the data to express the same patterns. All we really did was rotate the original coordinate system (defined by Variables 1 and 2) to a new coordinate system (defined by red and blue).
You may have guessed that the red and blue axes have special names: they are the principal components of this dataset. Principal components (PCs) are synthetic or composite axes that capture most of the variation. A PC is a linear combination of each of the original variables. This is easy to see in the figure above, because PC1 is defined by its coordinates. The same logic is true with more variables; it’s just harder to visualize.
13.5.1.2 PCA–more details
The procedure above illustrates the geometric interpretation of PCA. The general procedure is:
- Begin with the samples as a cloud of n points in a p-dimensional space.
- Center (and usually scale) the axes in the point cloud. This will place the origin of the new coordinate system at the p-dimensional centroid of the cloud.
- Rotate the axes to maximize the variance along the axes. As the angle of rotation \(\theta\) changes, the variance \(\sigma^{2}\) will also change.
- Continue to rotate the axes until the variance along each axis is maximized. Because the data are changed only by rotation, the Euclidean distances between them are preserved.
The other way PCA can be understood is in the language of linear algebra. The procedure is roughly given by:
- Calculate the variance-covariance matrix S of the data matrix A. This is a p \(\times\) p square matrix with the variances of each variable on the diagonal, and covariances between pairs of variables in the upper and lower triangles.
- Find the eigenvalues \(\lambda\) of S. Each eigenvalue represents a portion of the original total variance–the proportion corresponding to a particular principal component.
- Find the eigenvectors. For each eigenvalue \(\lambda\), there is an eigenvector that contains the coefficients of the linear equation for that principal component. Together the eigenvectors form a p \(\times\) p matrix, Y.
- Find the scores for the original samples on each principal component as \(\textbf{X} = \textbf{AY}\). The linear algebra method of PCA in R is illustrated below.
# generate some random data for PCA
set.seed(123)
n <- 50
x <- runif(n, 1, 20)
y <- 1.2 + 1.7*x + rnorm(n, 0, 15)
# produces data with a linear relationship between x and y
# data matrix: n rows * p columns
A <- cbind(x,y)
# standardize each variable
A <- apply(A, 2, scale)
# calculate variance-covariance matrix S
S <- cov(A)The variance-covariance matrix S contains the variances of the variables on the diagonal. Both variances are 1 because we scaled the variables (compare to cov(A) to see the difference). This matrix S is symmetric because the covariance function is reflexive; i.e., Cov(x,y) = Cov(y,x). The variance-covariance matrix is useful because it contains information about both the spread (variance) and orientation (covariance) in the data. For a dataset like ours with 2 variables, the variance-covariance matrix has 2 dimensions (one for each variable).
\[ \textbf{S}= \begin{bmatrix}Var(x) & Cov(x,y) \\ Cov(y,x) & Var(y) \end{bmatrix} \]
# calculate eigenvalues and eigenvectors
eigens <- eigen(S)
evals <- eigens$values
evecs <- eigens$vectorsPCA is all about defining a new coordinate system for the data that preserves Euclidean distances, but maximizes the variance captured on the axes of the new system. The axes of the new system are found as linear combinations of the original variables. This means that the new coordinate system will have as many dimensions as the original coordinate system.
The data in our example can be thought of as a matrix with two columns; each sample is defined by a vector of length two (one for each dimension). That vector simply contains the x and y coordinates of the sample. If the dataset is matrix X, then each point is a vector \(v_{i}\) where i = 1, 2, …, n (n = number of samples). For example, the vector [1, 2] corresponds to an observation with x = 1 and y = 2 (this vector is also a row of X).
To transform the points in the original coordinate system to a new coordinate system, we multiply each vector \(v_{i}\) by a p \(\times\) p transformation matrix T (recall that p is the number of dimensions) to get the transformed coordinates \(b_{i}\).
\[\textbf{T}v_{i}=b_{i}\]
Or written out fully:
\[\begin{bmatrix} \textbf{T}_{1,1} & \textbf{T}_{1,2} \\ \textbf{T}_{2,1} & \textbf{T}_{2,2} \end{bmatrix} \begin{bmatrix} x_{i} \\ y_{i} \end{bmatrix} =\begin{bmatrix}\textbf{T}_{1,1}x_{i} & \textbf{T}_{1,2}y_{i} \\ \textbf{T}_{2,1}x_{i} & \textbf{T}_{2,2}y_{i}\end{bmatrix}\]
It turns out that some vectors \(v_{i}\) have a very interesting property: when transformed by T, they change length but not direction. These vectors are called eigenvectors. The scalar (aka: constant) that defines the change in their length (aka: magnitude) is called an eigenvalue. This property is expressed compactly as:
\[\textbf{T}v_{i}=\lambda b_{i} \]
The interpretation of this expression is that transforming a coordinate \(v_{i}\) into a new coordinate system with matrix T is the same as multiplying \(v_{i}\) by the eigenvalue \(\lambda\). If the eigenvectors are collected into a new matrix V, and the eigenvalues are collected into a vector L, then
\[\textbf{S}\textbf{V}=\textbf{L}\textbf{V} \]
Put in terms of our 2-d example,
\[\begin{bmatrix}Var(x) & Cov(x,y) \\ Cov(y,x) & Var(y) \end{bmatrix} \begin{bmatrix} v_{1}\\v_{2} \end{bmatrix}= \begin{bmatrix}\lambda_{1}\\\lambda_{2} \end{bmatrix} \begin{bmatrix}v_{1}\\v_{2} \end{bmatrix} \]
Once the terms are solved (by the computer!), we can put the eigenvectors in descending order of their eigenvalues to get the principal components.
# calculate scores by matrix operations
pc <- A %*% evecs
# check that variances = eigenvalues and
# covariances = 0 (must be, by definition of PCA)
## close enough (<1e-16), probably a numerical limit involved
cov(pc)## [,1] [,2]
## [1,] 1.625446e+00 9.690887e-17
## [2,] 9.690887e-17 3.745539e-01## [1] 0.813 0.187The result shows us that about 81% of the variation is explained by PC1 alone, with the remainder explained by PC2. Notice that all of the variation in the dataset is associated with 1 and only 1 PC. This is part of the definition of PCA–the total variation among the samples does not change. All that changes is how we describe the variation (i.e., how we orient the axes used to describe the samples).
Why go through all of this trouble? Besides the benefit of understanding what PCA is doing, we can use the linear algebra to translate between the coordinate system of the original data, and the coordinates system defined by the PCs. The algebra is complicated, but it boils down to multiplying the matrix of PC scores by the transpose of the eigenvector matrix:
## [1] -4.440892e-16 4.440892e-16The “back-calculated” coordinates are off by at most 4.5 \(\times\) 10-16. The differences should technically be 0, but they are approximated to a very small number by R.
13.5.1.3 PCA in R (package vegan)
There are two methods for PCA in base R: prcomp() and princomp(). Both of these methods produce similar outputs, and the only major difference between them is the syntax for extracting results. For this course we are going to use the ordination functions in package vegan. Although designed for community ecology, vegan is widely used for ordination and multivariate analysis in many fields . Importantly, vegan is actively maintained and updated with new techniques as they are developed. Also importantly, vegan offers a common interface for many kinds of ordination.
The example below uses the bat brain dataset that we have used before. This dataset describes brain morphology and lifestyle in 63 species of bats (Hutcheon et al. (2002)). Download the dataset here and load it into R. It contains the following variables:
| Variable | Meaning |
|---|---|
species |
Species |
family |
Taxonomic family |
diet |
Herbivore, gleaner, hawker, or vampire |
bow |
Body weight (g) |
brw |
Brain weight (\(\mu\)g) |
aud |
Auditory nuclei volume (mm3) |
mob |
Main olfactory bulb volume (mm3) |
hip |
Hippcampus volume (mm3) |
The code below requires that you have the file in your R working directory.
## Warning: package 'rgl' was built under R version 4.3.3We are going to explore how brain morphology, measured as volumes of various brain parts, varies with taxonomy and lifestyle. First, we need to make sure that our data are suitable for PCA. We can inspect distributions of the variables with histograms.
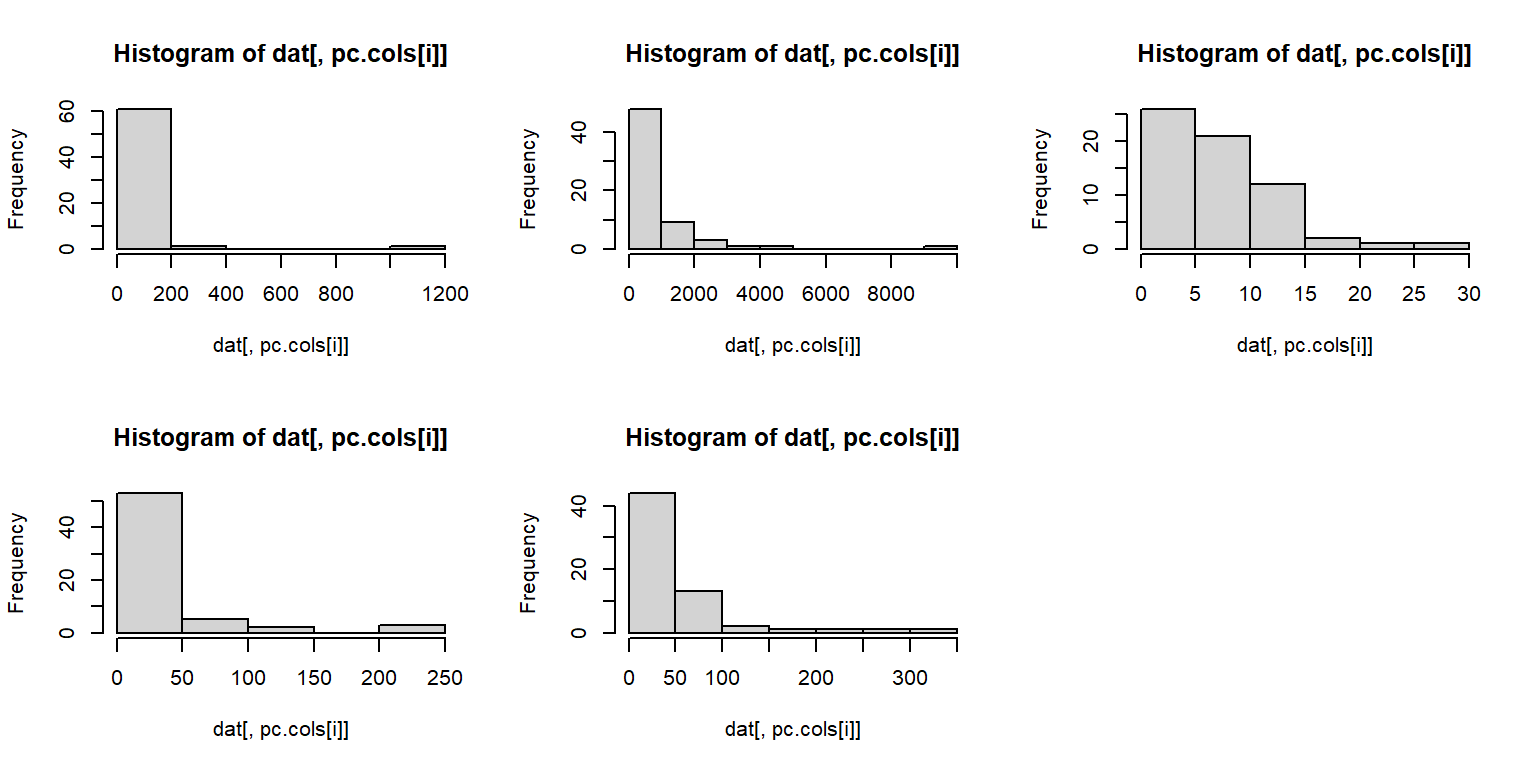
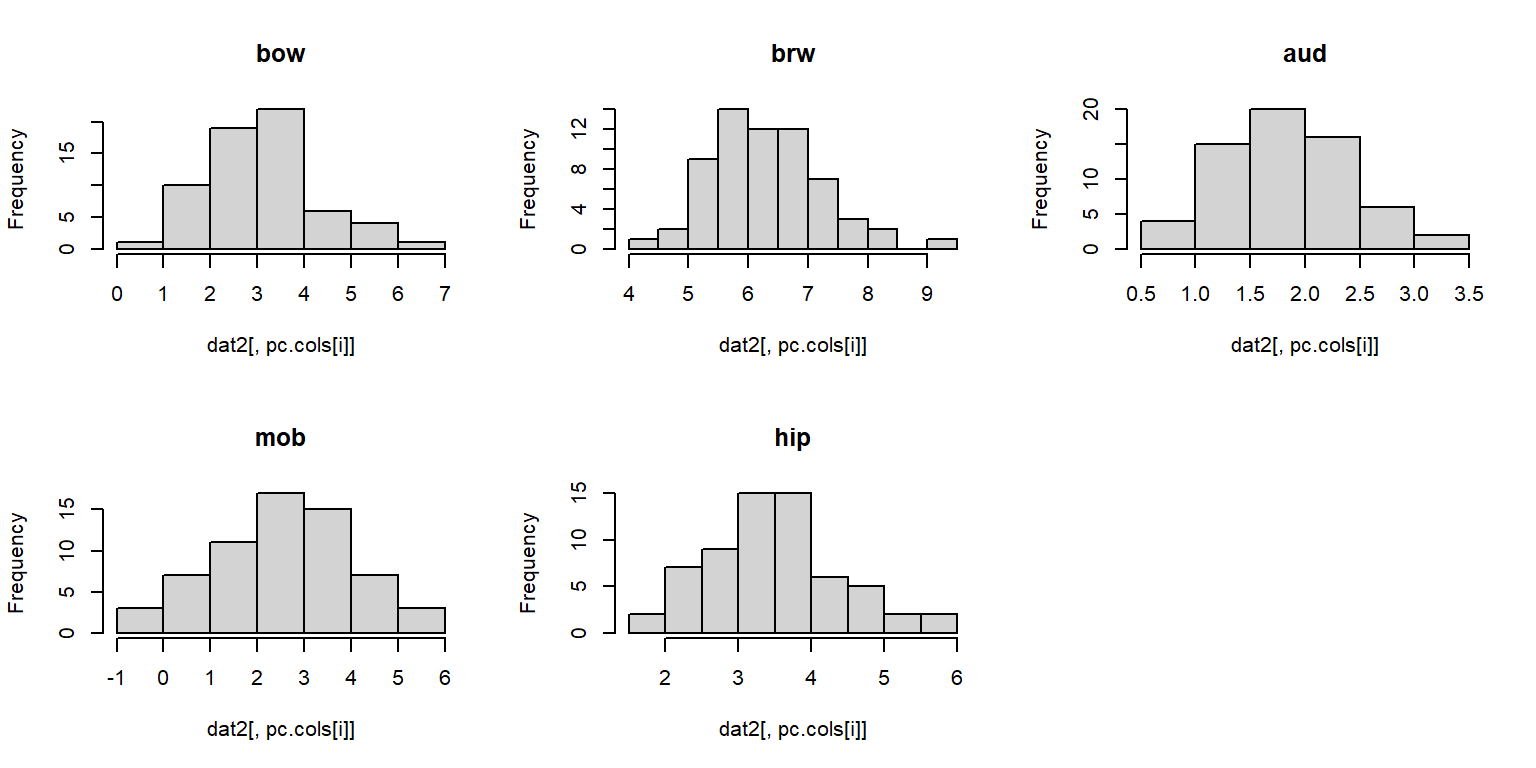
The histograms suggest that a log transform would be appropriate, because PCA requires multivariate normality.
dat2 <- dat
dat2[,pc.cols] <- apply(dat2[,pc.cols], 2, log)
par(mfrow=c(2,3))
for(i in 1:length(pc.cols)){
hist(dat2[,pc.cols[i]],
main=names(dat2)[pc.cols[i]])
}
Much better. We should also check to see if any of the variables are related to each other. It’s okay if they are, but such relationships need to be kept in mind when interpreting the PCA (or any ordination, for that matter). To explore relationships between the variables, we will use a pairs() plot and a function borrowed from the pairs() help page.
# borrowed from ?pairs examples
panel.cor <- function(x, y, digits = 2, prefix = "", cex.cor, ...)
{
r <- abs(cor(x, y))
txt <- format(c(r, 0.123456789), digits = digits)[1]
txt <- paste0(prefix, txt)
if(missing(cex.cor)) cex.cor <- 0.8/strwidth(txt)
text(0.5, 0.5, txt, cex = cex.cor * r)
}
# make our plot:
pairs(dat2[,pc.cols],
lower.panel = panel.smooth,
upper.panel = panel.cor,
gap=0)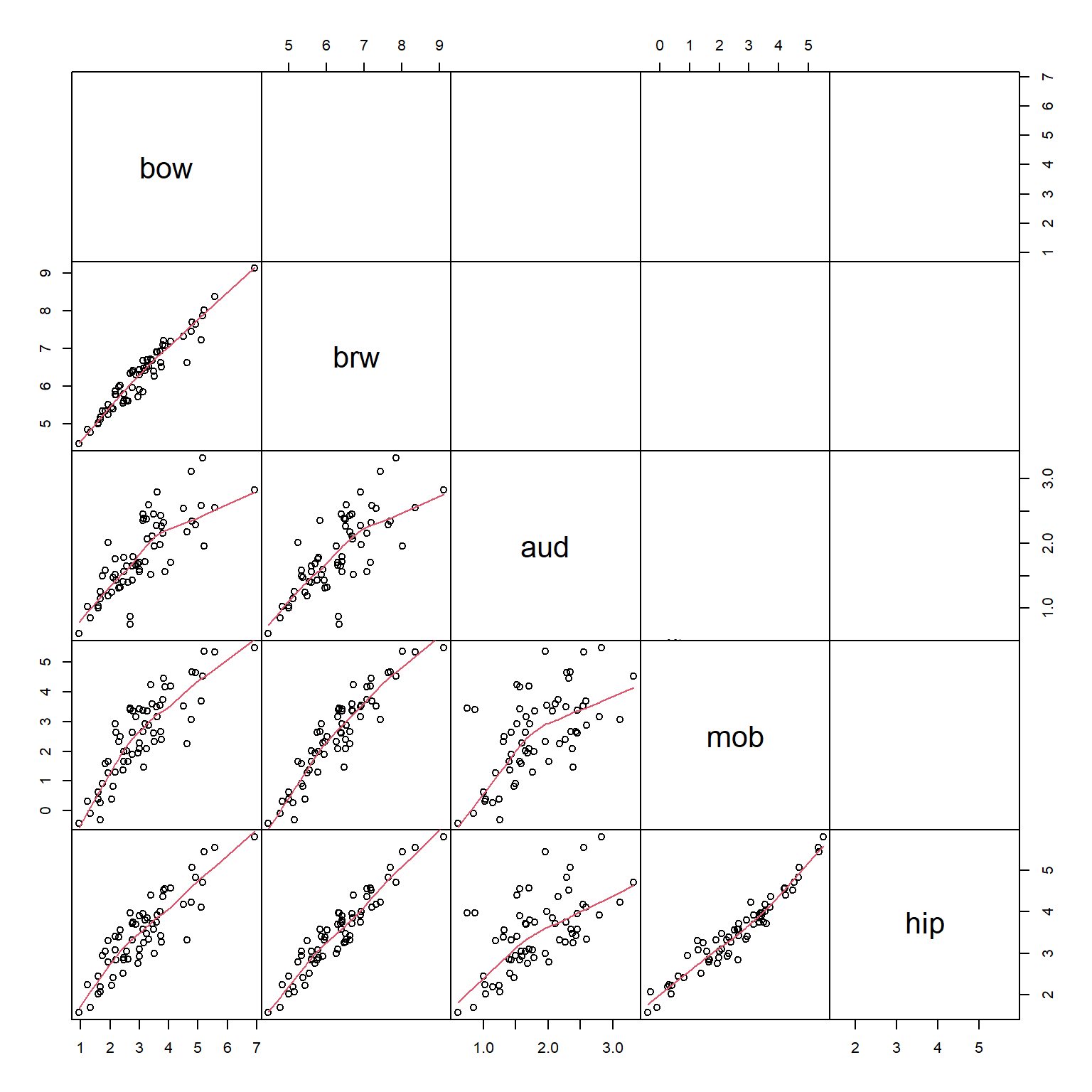
The scatterplot matrix suggests that every variable is closely related to every other variable. This makes sense for morphological data: the sizes of different body parts tend to scale with overall body size. We are interested in brain morphology independent of size, we can factor out size by dividing the volumes of each brain part by the body weight. Because the data are already on the log scale, the division is accomplished by subtracting the log-transformed body weight. The new values of brw, aud, mob, and hip are the sizes of those brain components with body size factored out. Neglecting to factor out body size or overall size prior to an ordination will result in an ordination dominated by body size.
dat3 <- dat2
dat3[,pc.cols[-1]] <- apply(dat3[,pc.cols], 1,
function(x){x[-1]-x[1]})
pairs(dat3[,pc.cols],
lower.panel = panel.smooth,
upper.panel = panel.cor,
gap=0)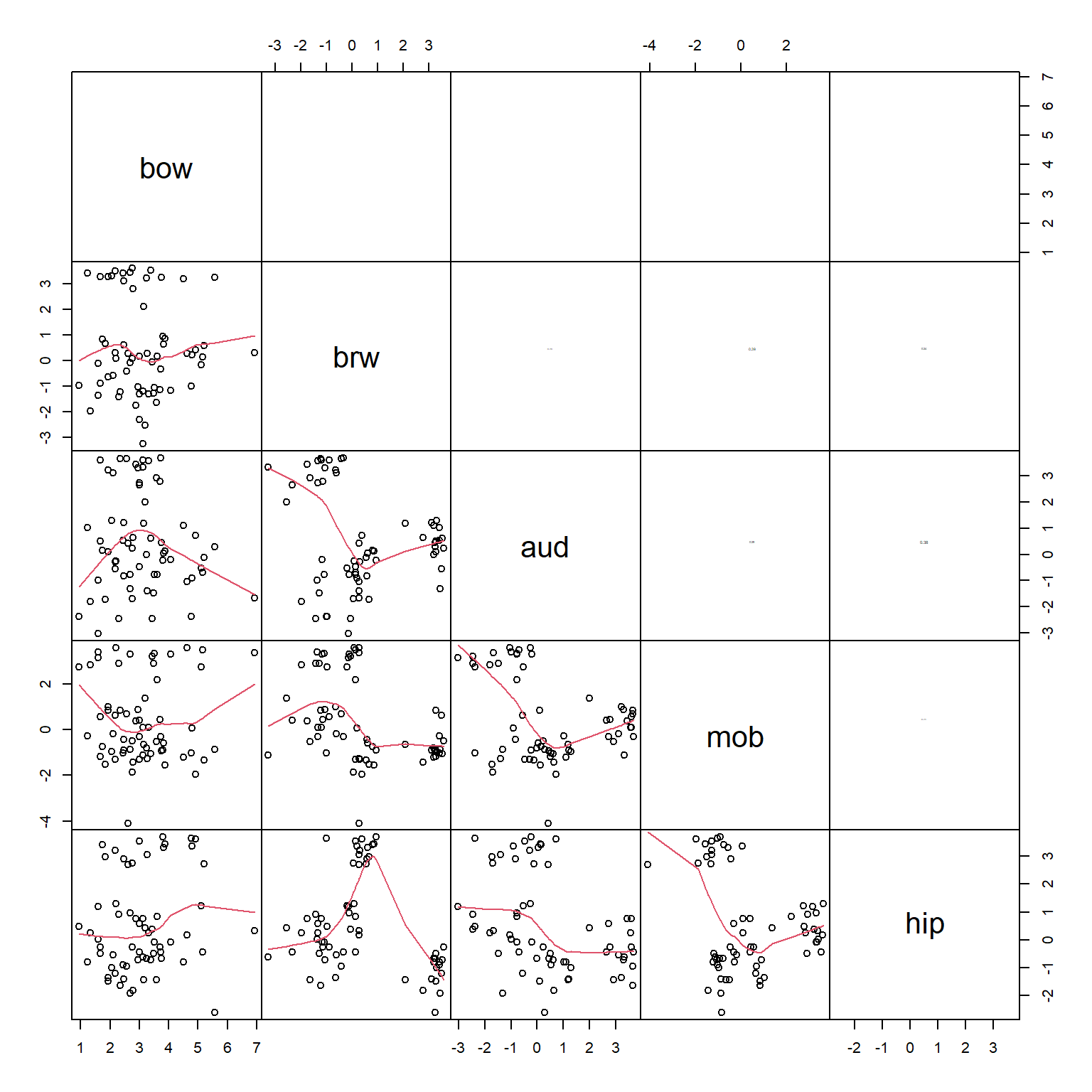
Next, use the function rda() from vegan to calculate the PCA. In this PCA we scale the variables (aka: standardize) by subtracting the mean and dividing by the SD. This has the effect of making each variable have mean = 0 and SD = 1. Scaling is not strictly required for PCA but is highly recommended. If values are not scaled, then the PCA will be dominated by the variables with the greatest values or by the observations with extreme values.
##
## Call:
## rda(X = dat3[, pc.cols], scale = TRUE)
##
## Partitioning of correlations:
## Inertia Proportion
## Total 5 1
## Unconstrained 5 1
##
## Eigenvalues, and their contribution to the correlations
##
## Importance of components:
## PC1 PC2 PC3 PC4 PC5
## Eigenvalue 1.4884 1.3471 1.0867 0.9389 0.13888
## Proportion Explained 0.2977 0.2694 0.2173 0.1878 0.02778
## Cumulative Proportion 0.2977 0.5671 0.7844 0.9722 1.00000The summary of the output contains most of what we need. Of greatest interest are the relative contributions of each PC. That is, how much of the overall variation is associated with each PC.
The overall variation is the sum of the variances of the original variables. The PCA was fit using centered and scaled values, so we need to scale the original data to see the variances that were used in the PCA. The scaling meant that each variable ended up with mean = 0 and variance = 1, so the total variance was equal to 5.
## bow brw aud mob hip
## 1 1 1 1 1That total variance of 5 was partitioned into 5 PCs. In PCA, data are ordinated on one PC for each of the original variables. Each PC is a combination of the original variables. The summary table for the PCA shows how the total variance was split up.
- The first row,
Eigenvalue, is the variance associated with each PC. The sum of the eigenvalues equals the total variance, 5. - The
Proportion Explainedrow shows the proportion of total variance captured on each PC. PC1 captures 29.8%, PC2 captured 26.9%, and so on. For example, the proportion of variance explained by PC1, 0.2977, is equal to the eigenvalue of PC1 divided by the total variance (1.4884 / 5). - The
Cumulative Proportionrow is the running total of proportion of variance explained, starting with PC1. The rule of thumb for PCA is that you should present and interpret enough PCs to capture \(\ge\) 80% of the variation. In this example, it takes 3 PCs to get up to about 80% of the variation explained). Two PCs is easier to deal with, but sometimes you need 3.
## Importance of components:
## PC1 PC2 PC3 PC4 PC5
## Eigenvalue 1.4884 1.3471 1.0867 0.9389 0.13888
## Proportion Explained 0.2977 0.2694 0.2173 0.1878 0.02778
## Cumulative Proportion 0.2977 0.5671 0.7844 0.9722 1.00000An alternative strategy for deciding how many PCs to interpret is to look at a screeplot, which shows the relative contributions of each PC to the overall variance. The variance is expressed as “Inertia”–the eigenvalues of the PCs. The proportion explained by each axis (seen in the table above), is simply the eigenvalues of the axes divided by the total of all eigenvalues. Some people prefer to present a screeplot that shows proportion of variance explained rather than the eigenvalues.
par(mfrow=c(1,2))
screeplot(p1, main="Eigenvalues")
# alternative version with proportion of variance explained
# instead of eigenvalues (variances)
prx <- 100*summary(p1)$cont$importance[2,]
barplot(prx, ylim=c(0, 30),
main="%Variance",
ylab="Proportion of variance explained")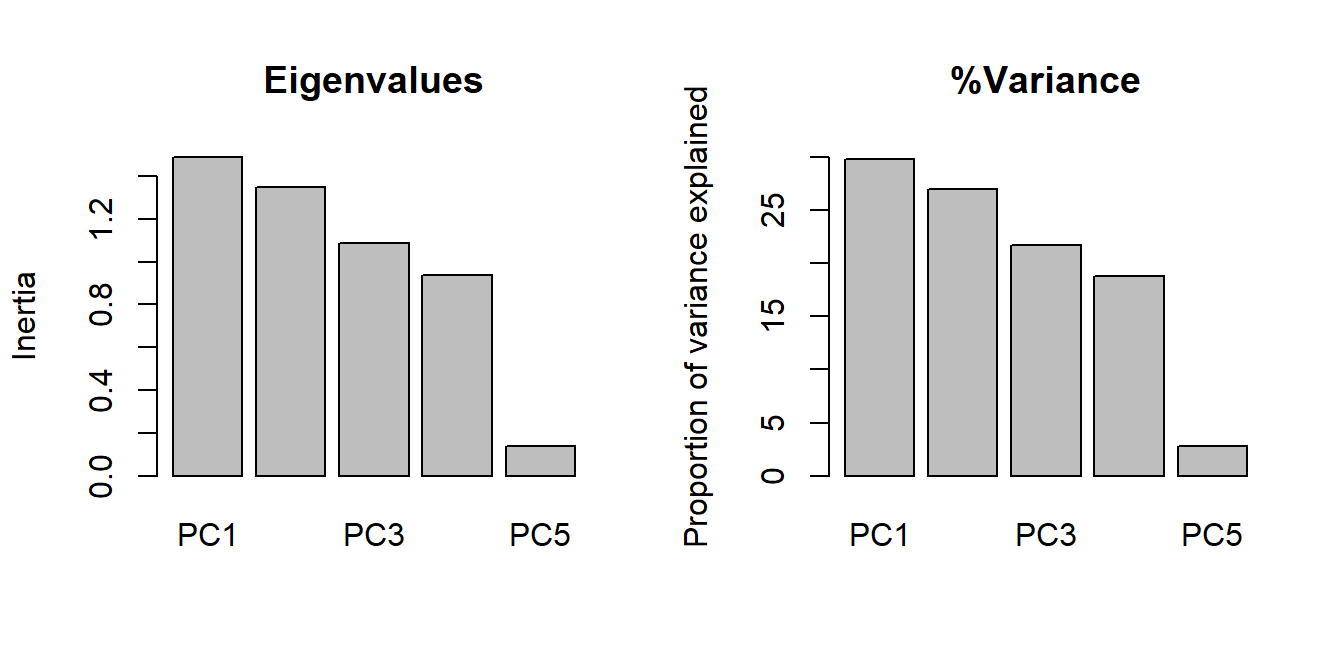
The loadings of the variables express how much each variable is associated with each PC. These values have two interpretations:
- First, they are the correlations between the variables and the PCs.
- Second, they are the coordinates for the biplot vectors (see below), which help us see the relationships between the ordination and the variables.
- Note: the biplot vectors implied by these coordinates are sometimes rescaled to more faithfully represent the relationships between variables. See Legendre and Legendre (2012) for a thorough explanation.
## PC1 PC2 PC3 PC4
## bow -0.2840062 0.1746469 0.1914720 0.92240824
## brw 0.3898723 0.5563058 -0.5292561 0.14392406
## aud 0.5555135 -0.3485255 0.5448121 0.14388004
## mob -0.4290023 -0.5917029 -0.4394228 0.09156649
## hip -0.5241200 0.4340967 0.4396748 -0.31521900
## attr(,"const")
## [1] 4.196048PC1 is most strongly correlated with aud (r = -0.55) and hip (r = 0.52). PC2 is most strongly correlated with mob (r = 0.59) and brw (r = -0.55). Ideally, each PC would have a few variables strongly correlated with it (r > 0.7), but that isn’t the case here. Interestingly, most of the variables are moderately correlated with first three axes. This suggests that none of the variables is strongly driving any of the PCs. We can check this with a biplot.
An ordination biplot is probably the most important tool for interpreting the relationships in the data captured by the ordination. It is called a biplot because it presents two kinds of data: similarity between the samples indicated by proximity in the ordination space; and relationships between some set of quantitative variables and the ordination axes. The samples are plotted as points; the variables are plotted as vectors radiating from the origin.
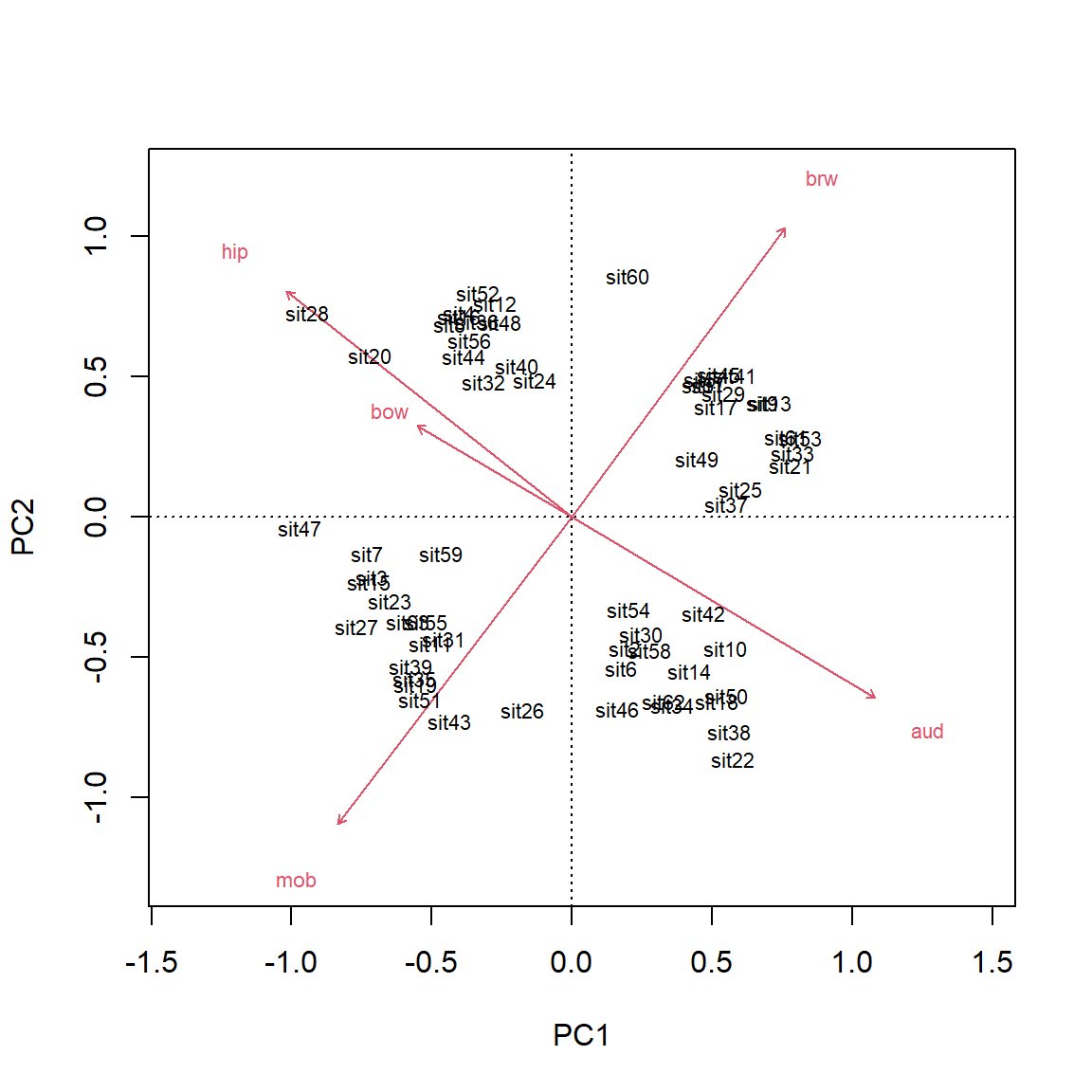
The biplot shows the points (by row name/number) and the five numeric variables that went into the PCA. Each vector shows the projection of a variable into the ordination space.
- The direction of a vector shows the direction (in ordination space) in which a variable increases. For example, samples in the upper left have increased
aud; samples in the upper right have increasedmob, and so on. A variable decreases in the direction opposite its vector: samples in the lower right have decreasedaud.- Compare the variable loadings with the biplot arrows. Do these values make sense?
- Relative angles of vectors reflect the correlation between the underlying variables.
- Variables whose vectors point in the same direction are positively correlated with each other; the smaller the angle between two vectors, the stronger the correlation (r approaching 1).
- Vectors perpendicular to each other are uncorrelated (r close to 0).
- Vectors pointing in opposite directions are negatively correlated with each other (r approaching -1).
- Correlation coefficients cannot be inferred directly from angles because of how the coordinates on the plot are scaled, but the angles do give a rough idea.
- The length of a vector indicates the strength of the correlation with the ordination space. Longer vectors indicate stronger correlations (|r |).
- Each variable vectors represents an axis of the original coordinate system.
- Shorter vectors have most of their length off the plane of the biplot.
- Longer vectors have more of their length near the plane of the biplot.
- The biplot is really a plane within the original data coordinate system defined by the PCs.
Because it took 3 PCs to get up to about 80% of the variation, we should present and interpret the first 3 PCs. We can plot other variables with the biplot() command.
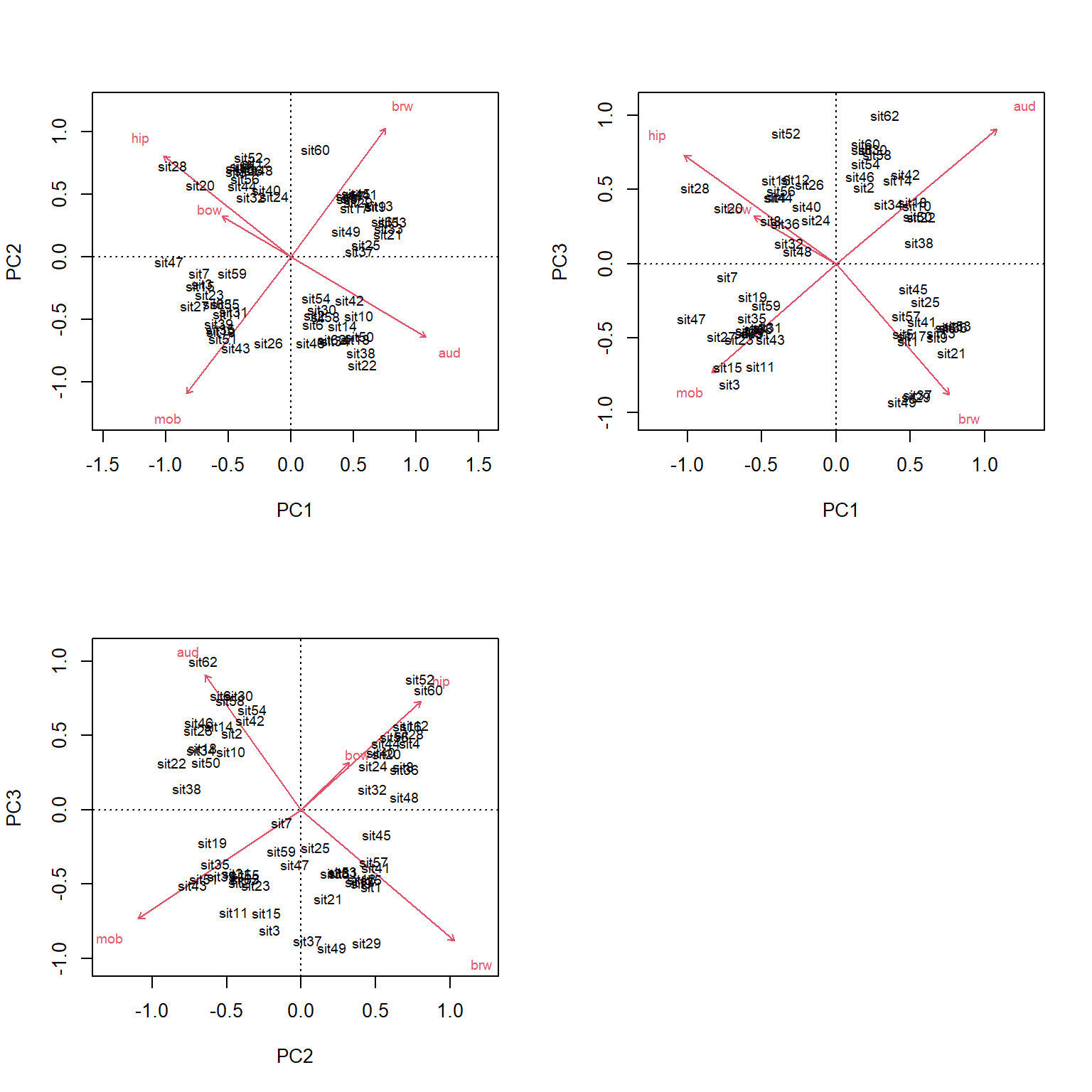
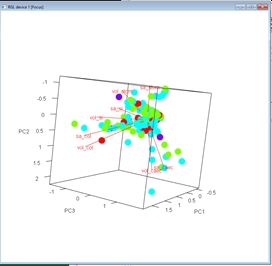
Even better, we can make a 3-d plot using the rgl package. Note that the code block below was not run to make this page; try running it on your machine. The plots made by plot3d() are cool because you can rotate them with the mouse. Exporting rgl figures to static image formats like .jpg can be tricky because you must specify the rotation angles, which can pretty much only be done by trial and error.
library(rgl)
par(mfrow=c(1,1))
px <- scores(p1, choices=1:3)$sites
plot3d(px[,1], px[,2], px[,3],
xlab="PC1", ylab="PC2", zlab="PC3")
We can add more information to the biplots to help us make sense of the data. Let’s color-code the diets.
diets <- sort(unique(dat3$diet))
cols <- rainbow(length(diets))
use.cols <- cols[match(dat3$diet, diets)]
par(mfrow=c(1,1))
px <- scores(p1, choices=1:3)$sites
vx <- scores(p1, choices=1:3)$species
plot3d(px[,1], px[,2], px[,3],
xlab="PC1", ylab="PC2", zlab="PC3",
col=use.cols, size=50)
for(i in 1:nrow(vx)){
segments3d(c(0, vx[i,1]), c(0, vx[i,2]), c(0, vx[i,3]), col="red")
text3d(vx[i,1], vx[i,2], vx[i,3], rownames(vx)[i], col="red")
}
The biplot() command in vegan isn’t very flexible, so we if we want a nicer-looking plot we will need to construct it manually.
px <- scores(p1, choices=1:3)$sites
vx <- scores(p1, choices=1:3)$species
diets <- sort(unique(dat3$diet))
cols <- rainbow(length(diets))
use.cols <- cols[match(dat3$diet, diets)]
par(mfrow=c(2,2))
plot(px[,1], px[,2], pch=16, cex=1.4, col=use.cols,
xlab="PC1", ylab="PC2", xlim=c(-1.5, 1.5), ylim=c(-1.5, 1.5))
segments(0, 0, vx[,1], vx[,2], col="red")
text(vx[,1], vx[,2], rownames(vx), col="red")
plot(px[,1], px[,3], pch=16, cex=1.4, col=use.cols,
xlab="PC1", ylab="PC3", xlim=c(-1.5, 1.5), ylim=c(-1.5, 1.5))
segments(0, 0, vx[,1], vx[,3], col="red")
text(vx[,1], vx[,3], rownames(vx), col="red")
plot(px[,2], px[,3], pch=16, cex=1.4, col=use.cols,
xlab="PC2", ylab="PC3", xlim=c(-1.5, 1.5), ylim=c(-1.5, 1.5))
segments(0, 0, vx[,2], vx[,3], col="red")
text(vx[,2], vx[,3], rownames(vx), col="red")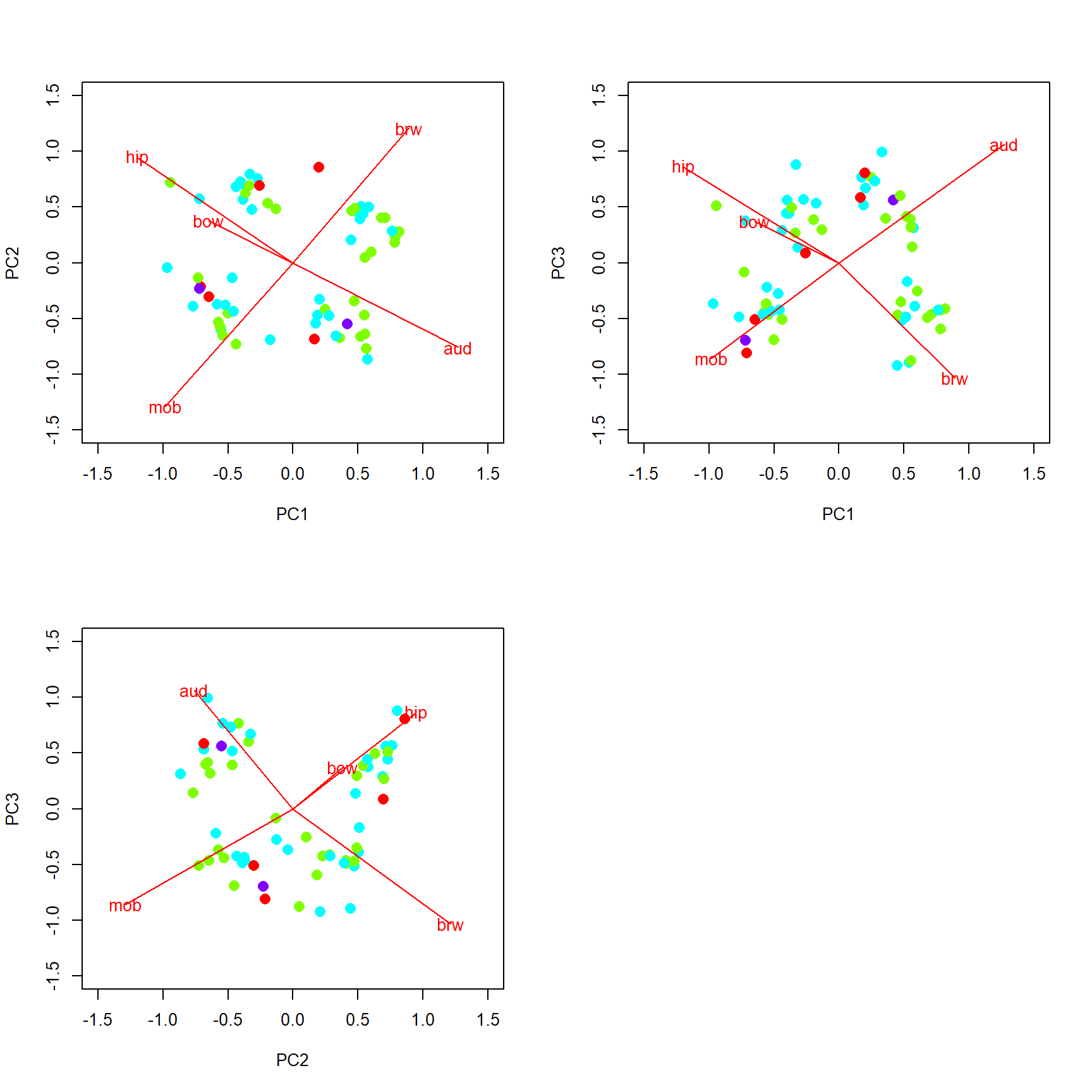
13.5.1.4 Application of PCA: PC regression
Because PCs capture information about multiple variables at once, they can be used to represent those variables in other statistical methods. For example, a PC that represents many measurements of body parts or tree species composition or gene expression can be used as a predictor variable in a logistic regression or as a response variable. This practice is sometimes called PC regression. The example below uses the iris dataset to illustrate using principal components of flower morphology to predict species identity.
library(vegan)
# grab numeric variables
dat <- iris[,1:4]
# standardize each variable
dat <- apply(dat, 2, scale)
# fit PCA with vegan::rda()
p1 <- rda(dat)
# examine output
summary(p1)##
## Call:
## rda(X = dat)
##
## Partitioning of variance:
## Inertia Proportion
## Total 4 1
## Unconstrained 4 1
##
## Eigenvalues, and their contribution to the variance
##
## Importance of components:
## PC1 PC2 PC3 PC4
## Eigenvalue 2.9185 0.9140 0.14676 0.020715
## Proportion Explained 0.7296 0.2285 0.03669 0.005179
## Cumulative Proportion 0.7296 0.9581 0.99482 1.000000# make some colors to label species
use.col <- rainbow(3)[match(iris$Species,levels(iris$Species))]
# extract scores of samples (px) and biplot vectors (vx)
px <- scores(p1, display="sites")
vx <- scores(p1,display="species")
# make a plot of the flowers in PCA space
plot(px[,1], px[,2], col=use.col, pch=16,
xlim=c(-3, 3), ylim=c(-3, 3),
xlab="PC1", ylab="PC2")
segments(0, 0, vx[,1], vx[,2], col="red")
text(vx[,1], vx[,2], rownames(vx), col="red")
legend("topleft", legend=levels(iris$Species),
pch=16, col=rainbow(3))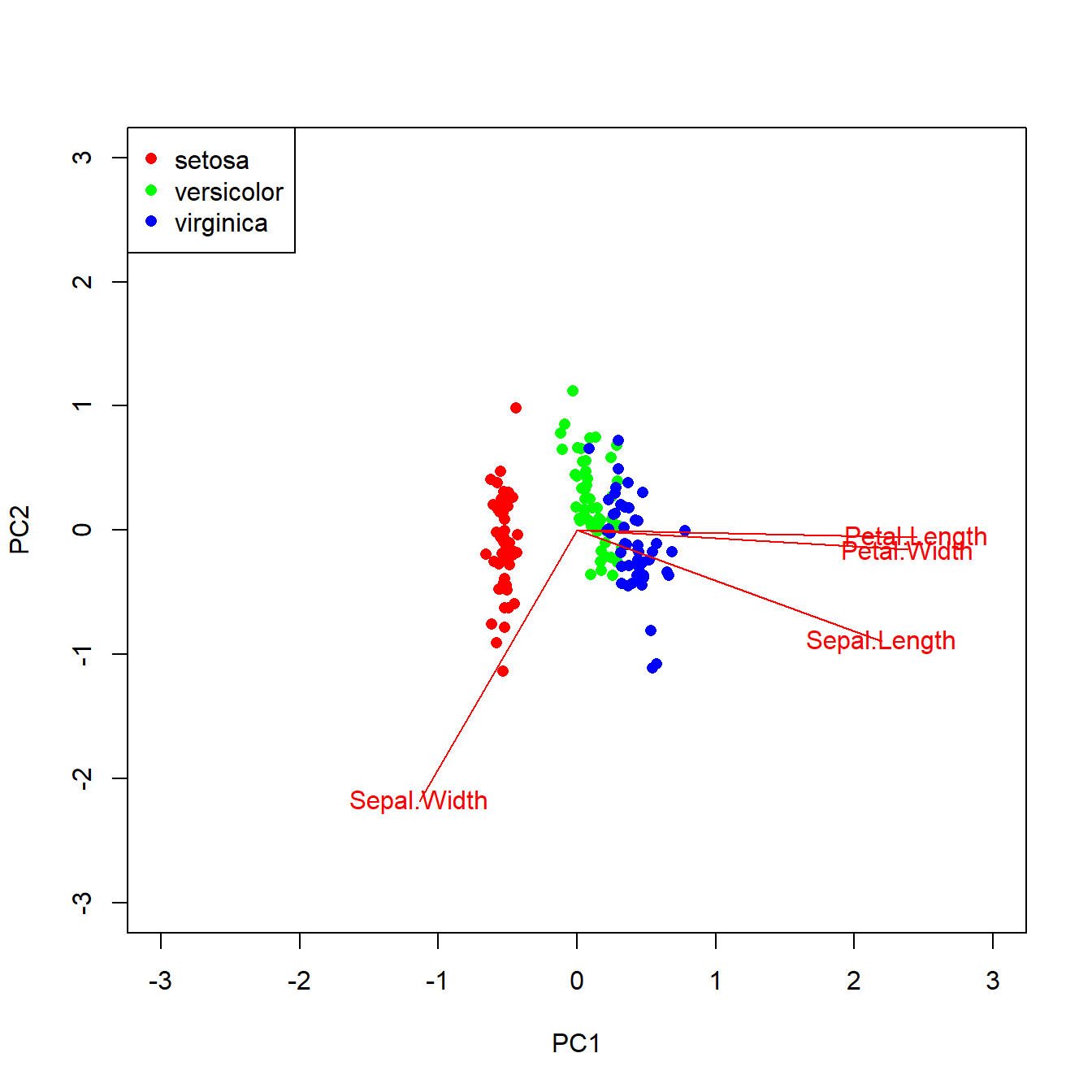
The ordination reveals that 73% of variation is explained by PC1. The figure shows that the species fall out very cleanly along PC1, with is associated with petal morphology. Let’s use PC1 as a predictor for species in a logistic regression.
dat2 <- data.frame(y=iris$Species, pc1=px[,1])
dat2$z <- ifelse(dat2$y == "virginica", 1, 0)
mod1 <- glm(z~pc1, data=dat2, family=binomial)
summary(mod1)##
## Call:
## glm(formula = z ~ pc1, family = binomial, data = dat2)
##
## Coefficients:
## Estimate Std. Error z value Pr(>|z|)
## (Intercept) -6.023 1.393 -4.323 1.54e-05 ***
## pc1 23.366 5.162 4.526 6.00e-06 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## (Dispersion parameter for binomial family taken to be 1)
##
## Null deviance: 190.954 on 149 degrees of freedom
## Residual deviance: 50.108 on 148 degrees of freedom
## AIC: 54.108
##
## Number of Fisher Scoring iterations: 9The logistic regression results suggest that for every unit increase in PC1, the odds ratio of a flower being Iris virginica increases by 23. That’s a very strong signal. Just for fun, below are the model predictions of probability of being I. virginica and the ROC curve. Both confirm visually what the coefficients table above suggested, that PC1 is a very reliable predictor of Iris species (at least in this dataset).
n <- 50
prx <- seq(min(dat2$pc1), max(dat2$pc1), length=n)
dx <- data.frame(pc1=prx)
pred <- predict(mod1, newdata=data.frame(dx),
type="link", se.fit=TRUE)
mn <- plogis(pred$fit)
ll <- plogis(qnorm(0.025, pred$fit, pred$se.fit))
uu <- plogis(qnorm(0.975, pred$fit, pred$se.fit))
par(mfrow=c(1,1), mar=c(5.1, 5.1, 1.1, 1.1),
lend=1, las=1, cex.axis=1.3, cex.lab=1.3,
bty="n")
plot(prx, mn, type="n", xlab="PC1",
ylab=expression(P(italic(virginica))),
ylim=c(-0.1,1.1))
points(prx, ll, type="l", lty=2)
points(prx, uu, type="l", lty=2)
points(prx, mn, type="l", lwd=2)
points(dat2$pc1, jitter(dat2$z, amount=0.05), xpd=NA)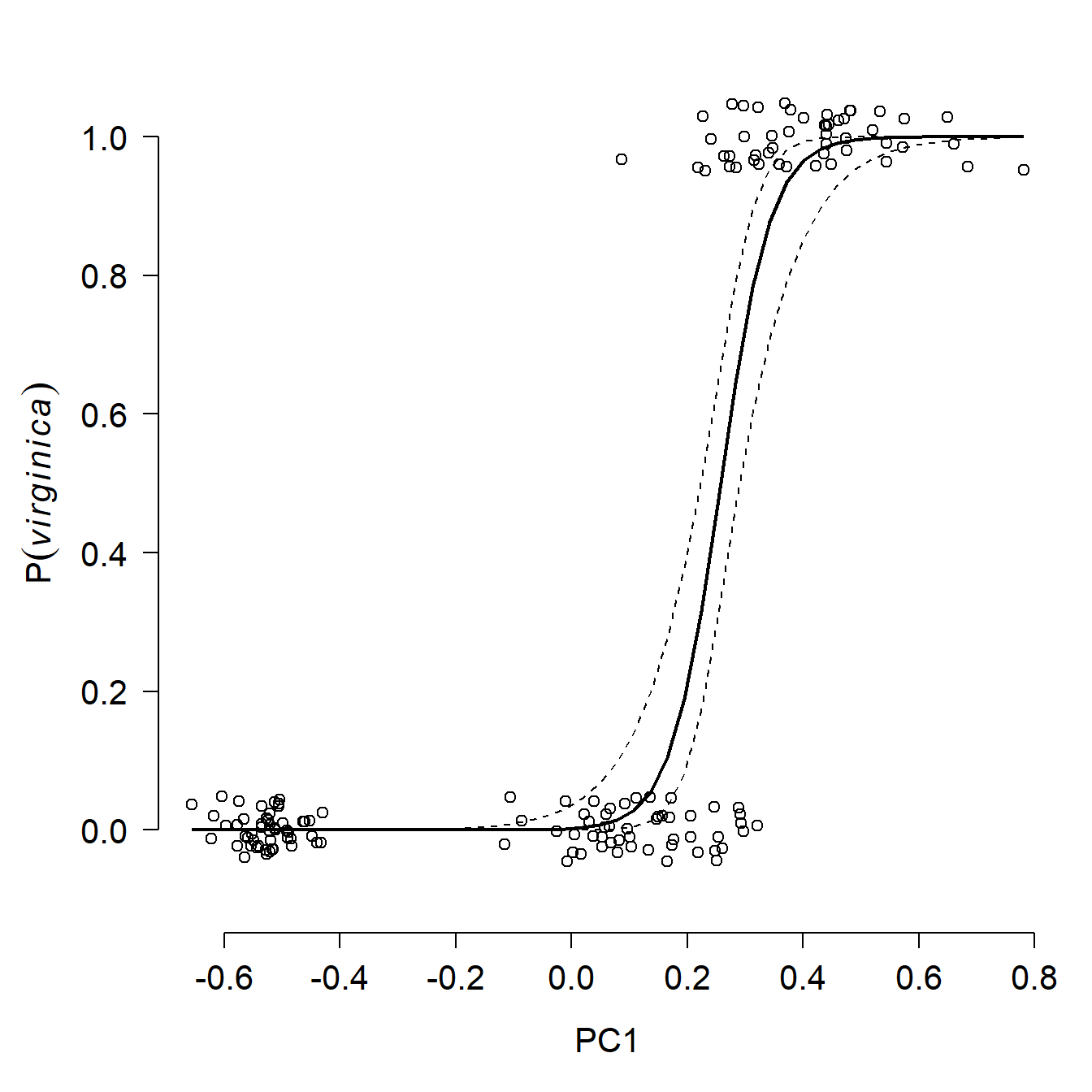
## Warning: package 'pROC' was built under R version 4.3.3## Type 'citation("pROC")' for a citation.##
## Attaching package: 'pROC'## The following objects are masked from 'package:stats':
##
## cov, smooth, var## Setting levels: control = 0, case = 1## Setting direction: controls < cases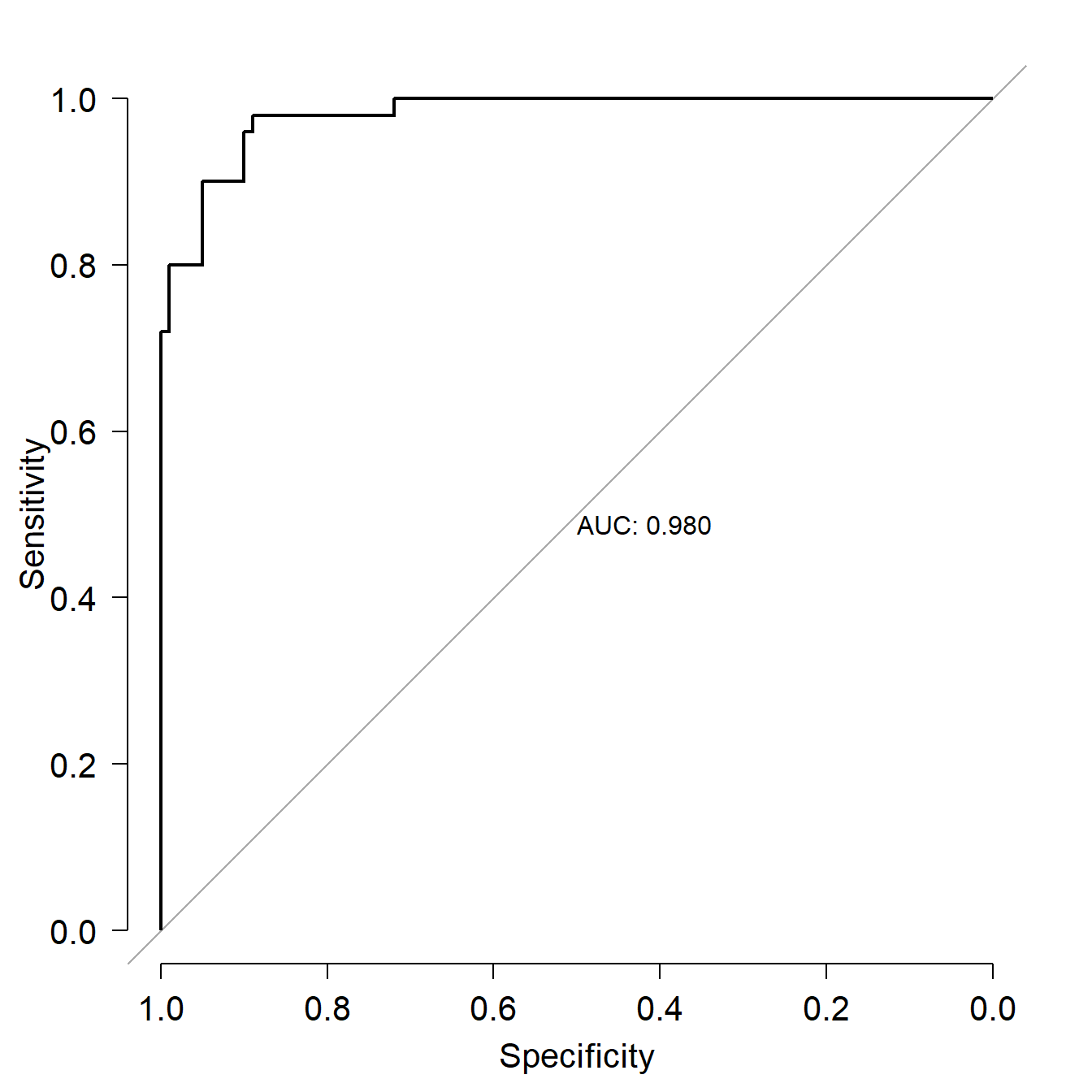
##
## Call:
## roc.formula(formula = dat2$z ~ p1, plot = TRUE, print.auc = TRUE)
##
## Data: p1 in 100 controls (dat2$z 0) < 50 cases (dat2$z 1).
## Area under the curve: 0.9804Going the other way, modeling PC scores in response to predictor variables, is tricky but it can be done. Usually this is only acceptable when there is a clear relationship between the modeled PC and several of the original variables that went into the PCA. Treating a PC as a dependent variable is an elegant way to get around the problem of having multiple collinear response variables. Conversely, treating a PC as a predictor variable is a way of dealing with multiple collinear predictor variables. Axes from other ordination techniques can be used in this manner, but require careful biological and statistical justification as well as very cautious interpretation.
13.5.2 NMDS and other ordination methods
PCA and many related techniques are based on linear algebra and eigenvalues. This is fine for datasets where variables are mostly linearly related to each other, or can be transformed to be linearly related. Most of the eigenvalue-based techniques also require data to be (mostly) multivariate normal distributed.
If relationships between variables are non-linear, or if the many other assumptions of eigenvalue-based ordination cannot be met, then the next best option is often a non-parametric ordination technique called nonmetric multidimensional scaling (NMDS or NMS). Unlike PCA, which solves linear algebra problems to extract synthetic gradients (“principal components”), NMDS works by trying iteratively to arrange the samples into a reduced dimensional space that preserves the rank order of the distance matrix.
13.5.2.1 NMDS simple explanation
Let’s start with a simple example. Download the dataset state_caps.csv, put it in your R home directory, and load it into R. This dataset contains the latitudes and longitudes of the state capitals of the US. For simplicity, we will use only the lower 48 states.
library(vegan)
in.name <- "state_caps.csv"
dat <- read.csv(in.name, header=TRUE)
dat <- dat[which(!dat$state %in% c("Alaska", "Hawaii")),]
# set rownames so the city names will carry through to the
# distance matrix
rownames(dat) <- dat$cap
dat <- dat[,c("long", "lat")]Use function vegdist() in package vegan to calculate Euclidean distances between the cities103. Then print the object d1 to the console and take a look (not shown).
The distance matrix gives the distance between each pair of cities, identified by row labels.
If you plot latitude vs. longitude, you will get a reasonable map of the continental US (CONUS).
Wouldn’t it be neat if we could recover the actual arrangement of capitals shown above just using their distance matrix? It turns out, we can, with NMDS. The main function for NMDS is metaMDS() in package vegan. NMDS involves random sampling, so set the random number seed for reproducibility.
## 'comm' has negative data: 'autotransform', 'noshare' and 'wascores' set to FALSE## Run 0 stress 0
## Run 1 stress 0.02824041
## Run 2 stress 9.688201e-05
## ... Procrustes: rmse 0.0003258308 max resid 0.0008680344
## ... Similar to previous best
## Run 3 stress 9.741634e-05
## ... Procrustes: rmse 0.0003391501 max resid 0.0009861631
## ... Similar to previous best
## Run 4 stress 9.614493e-05
## ... Procrustes: rmse 0.0003316108 max resid 0.00101616
## ... Similar to previous best
## Run 5 stress 9.839223e-05
## ... Procrustes: rmse 0.0003366584 max resid 0.001019179
## ... Similar to previous best
## Run 6 stress 9.938774e-05
## ... Procrustes: rmse 0.0003421181 max resid 0.001056077
## ... Similar to previous best
## Run 7 stress 9.747501e-05
## ... Procrustes: rmse 0.0003420786 max resid 0.001042044
## ... Similar to previous best
## Run 8 stress 9.688222e-05
## ... Procrustes: rmse 0.0003407193 max resid 0.001040716
## ... Similar to previous best
## Run 9 stress 9.042907e-05
## ... Procrustes: rmse 0.0003277819 max resid 0.0009954318
## ... Similar to previous best
## Run 10 stress 9.585724e-05
## ... Procrustes: rmse 0.0003388215 max resid 0.001045013
## ... Similar to previous best
## Run 11 stress 9.623688e-05
## ... Procrustes: rmse 0.0003381601 max resid 0.001029097
## ... Similar to previous best
## Run 12 stress 0.04810304
## Run 13 stress 9.271431e-05
## ... Procrustes: rmse 0.0003274582 max resid 0.000996862
## ... Similar to previous best
## Run 14 stress 9.821812e-05
## ... Procrustes: rmse 0.0003434694 max resid 0.001046526
## ... Similar to previous best
## Run 15 stress 9.886879e-05
## ... Procrustes: rmse 0.000344009 max resid 0.001069766
## ... Similar to previous best
## Run 16 stress 9.538052e-05
## ... Procrustes: rmse 0.0003364742 max resid 0.001031398
## ... Similar to previous best
## Run 17 stress 0.02824038
## Run 18 stress 9.633286e-05
## ... Procrustes: rmse 0.0003317048 max resid 0.000937519
## ... Similar to previous best
## Run 19 stress 0.02824036
## Run 20 stress 9.744164e-05
## ... Procrustes: rmse 0.0003414834 max resid 0.001047844
## ... Similar to previous best
## *** Best solution repeated 16 times## Warning in metaMDS(dat, distance = "euclidean"): stress is (nearly) zero: you
## may have insufficient data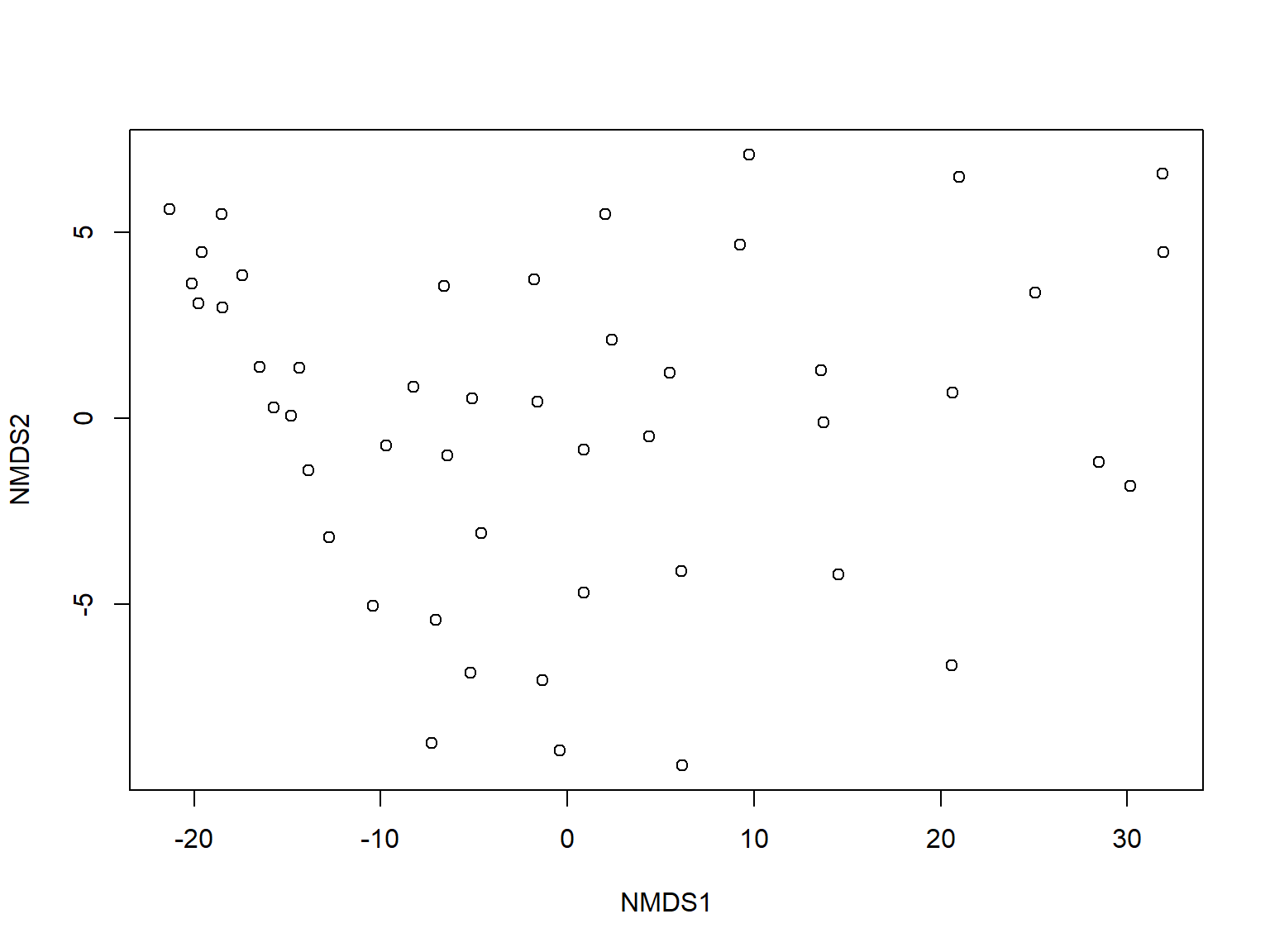
Notice anything odd? The arrangement of the cities, or relative positions, are mostly correct. However, the cities are flipped east to west! This is because NMDS only considers relative position, not absolute position. NMDS positions are arbitrary, so we can rotate or flip the axes to make better sense of them. We’ll flip the first axis (NMDS1) by multiplying it by -1.
Much better. The coordinates aren’t quite the same as the original data, but the relative positions of the cities are correct. We can confirm this with a stress plot.
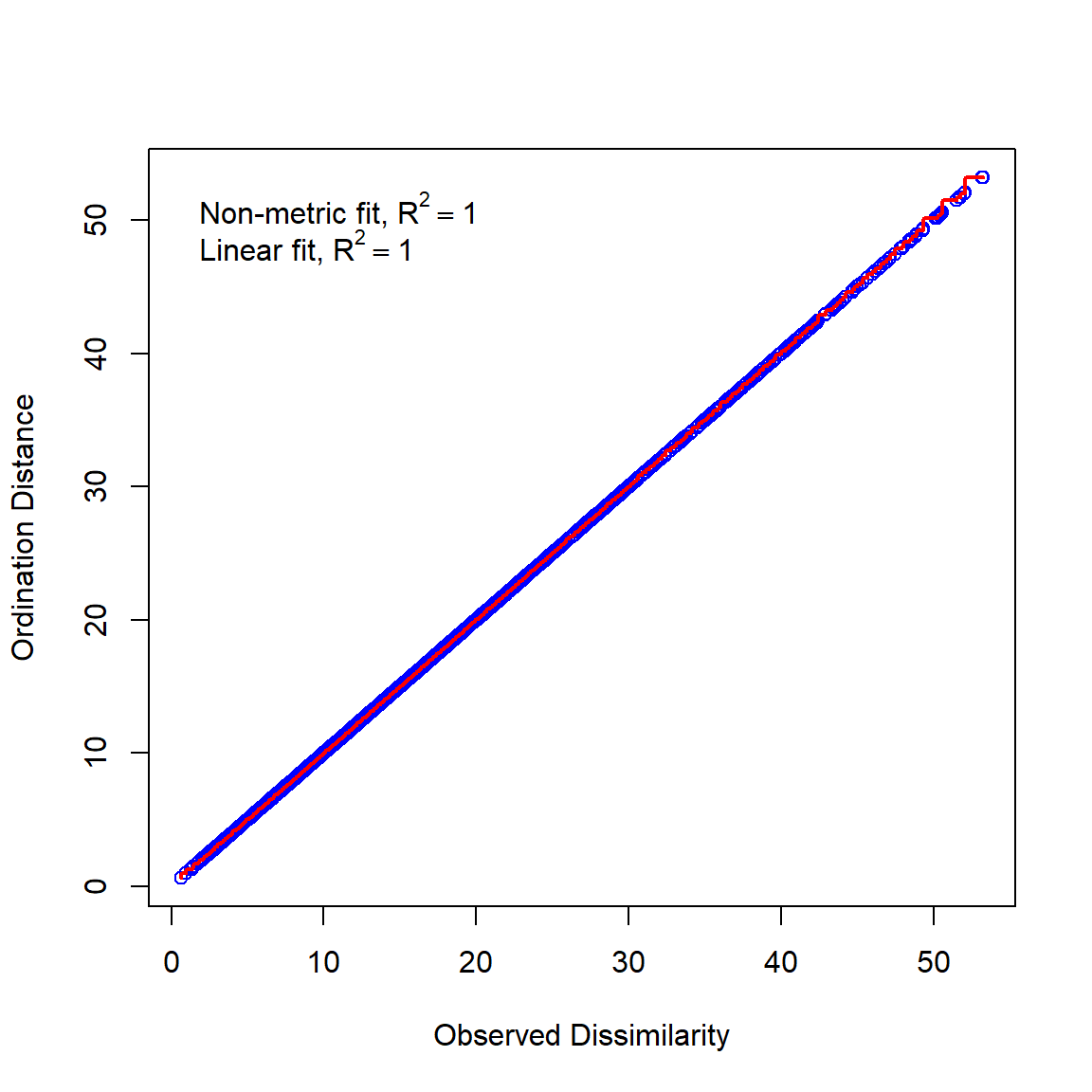
This chart shows that the distances between points in the NMDS space (Ordination Distance) are nearly identical to the distances between points in the original data space (Observed Dissimilarity). A good NMDS fit will have nearly all of the points on the red line of equality.
13.5.2.2 NMDS more complicated explanation
Like PCA, NMDS is a technique for reducing the dimensionality of data. The general approach of NMDS is to start with a cloud of n samples (points) in p dimensions (variables), and try to position the points into <p dimensions in a way that preserves the relative distances between the points. Consider the example below, which shows a 3-d dataset with variables X, Y, and Z.
The code below was not run for this tutorial, but a screenshot of the result is shown below.
library(rgl)
par(mfrow=c(1,1))
plot3d(x, y, z,
xlab="X", ylab="Y", zlab="Z",
xlim=c(0,10), ylim=c(0,10), zlim=c(0,10))
Or more prosaically:
par(mfrow=c(2,2))
plot(x, y, xlim=c(0, 10), ylim=c(0, 10))
plot(x, z, xlim=c(0, 10), ylim=c(0, 10))
plot(y,z, xlim=c(0, 10), ylim=c(0, 10))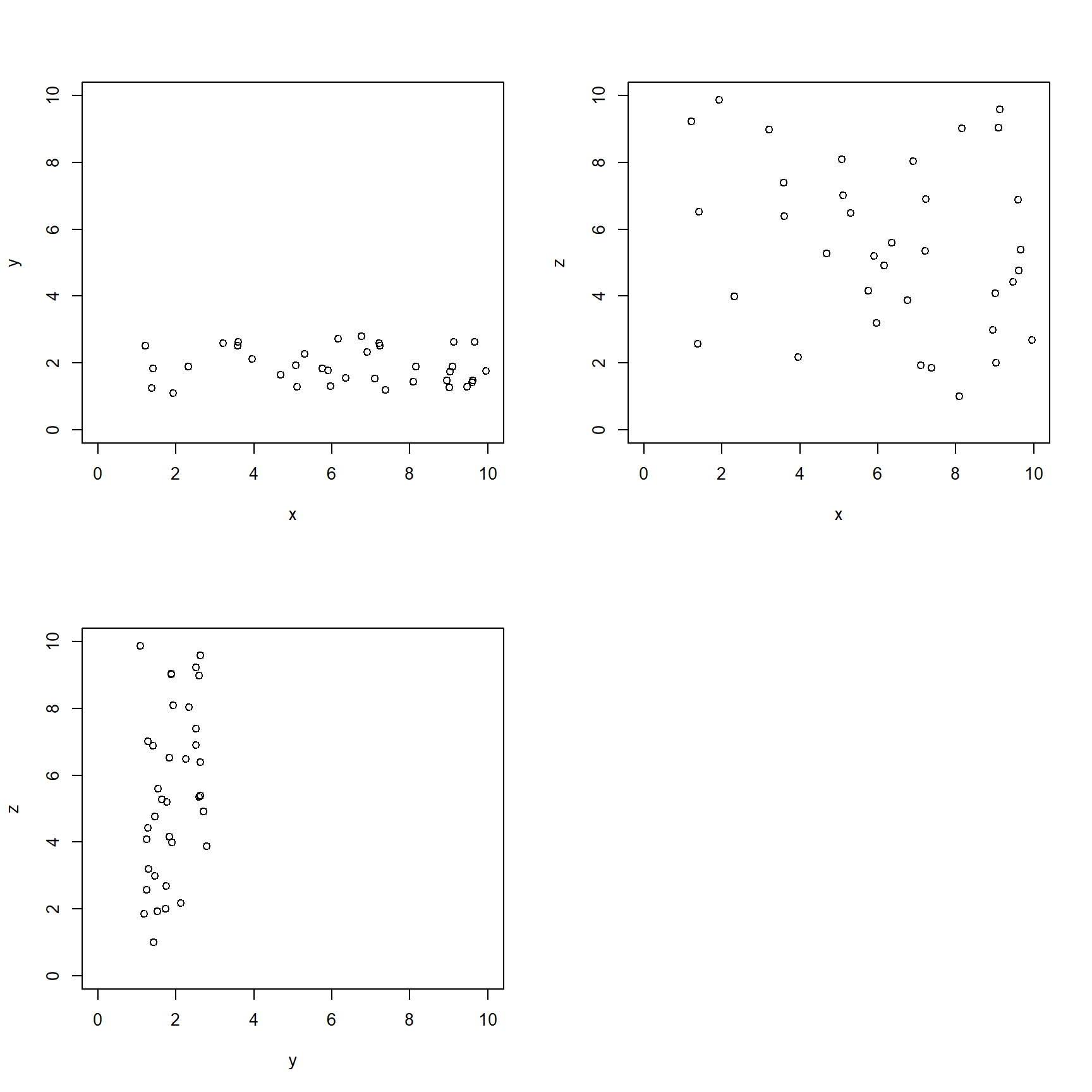
The scatterplots suggest that most of the variation is tied up in X and Z, with very little in Y. If we wanted to present the data in two dimensions, we could use NMDS to arrange the points in a 2-d space that preserves the relative distances. Data can be passed directly to metaMDS(), in which case it will calculate the distance matrix for you. Alternatively, you can supply a distance matrix. The function will figure out what to do based on what your input.
As always, set the random number seed for reproducibility.
## Wisconsin double standardization
## Run 0 stress 0.02846602
## Run 1 stress 0.02846602
## ... Procrustes: rmse 4.316137e-06 max resid 1.726271e-05
## ... Similar to previous best
## Run 2 stress 0.02846602
## ... Procrustes: rmse 1.118154e-05 max resid 4.018889e-05
## ... Similar to previous best
## Run 3 stress 0.02846602
## ... New best solution
## ... Procrustes: rmse 6.79216e-06 max resid 2.56478e-05
## ... Similar to previous best
## Run 4 stress 0.02846602
## ... Procrustes: rmse 7.699265e-06 max resid 2.638313e-05
## ... Similar to previous best
## Run 5 stress 0.02846602
## ... Procrustes: rmse 9.363497e-06 max resid 3.897864e-05
## ... Similar to previous best
## Run 6 stress 0.02846602
## ... New best solution
## ... Procrustes: rmse 2.322943e-06 max resid 7.365495e-06
## ... Similar to previous best
## Run 7 stress 0.02846602
## ... Procrustes: rmse 3.750166e-06 max resid 1.250864e-05
## ... Similar to previous best
## Run 8 stress 0.02846602
## ... Procrustes: rmse 6.108855e-06 max resid 2.128185e-05
## ... Similar to previous best
## Run 9 stress 0.02846602
## ... Procrustes: rmse 4.354076e-06 max resid 1.548638e-05
## ... Similar to previous best
## Run 10 stress 0.02846602
## ... Procrustes: rmse 1.755597e-06 max resid 5.736735e-06
## ... Similar to previous best
## Run 11 stress 0.02846602
## ... Procrustes: rmse 5.436307e-06 max resid 2.010142e-05
## ... Similar to previous best
## Run 12 stress 0.02846602
## ... Procrustes: rmse 1.012844e-06 max resid 3.324696e-06
## ... Similar to previous best
## Run 13 stress 0.02846602
## ... Procrustes: rmse 4.858257e-06 max resid 1.845511e-05
## ... Similar to previous best
## Run 14 stress 0.11564
## Run 15 stress 0.11564
## Run 16 stress 0.02846602
## ... Procrustes: rmse 3.743779e-06 max resid 1.643431e-05
## ... Similar to previous best
## Run 17 stress 0.02846602
## ... Procrustes: rmse 3.719871e-06 max resid 1.260728e-05
## ... Similar to previous best
## Run 18 stress 0.02846602
## ... Procrustes: rmse 5.596345e-06 max resid 2.38461e-05
## ... Similar to previous best
## Run 19 stress 0.11564
## Run 20 stress 0.11564
## *** Best solution repeated 11 times##
## Call:
## metaMDS(comm = dat)
##
## global Multidimensional Scaling using monoMDS
##
## Data: wisconsin(dat)
## Distance: bray
##
## Dimensions: 2
## Stress: 0.02846602
## Stress type 1, weak ties
## Best solution was repeated 11 times in 20 tries
## The best solution was from try 6 (random start)
## Scaling: centring, PC rotation, halfchange scaling
## Species: expanded scores based on 'wisconsin(dat)'The output tells us a lot about the fit. We got a 2-d fit (the default), used the Bray-Curtis distance metric (the default), and variables were centered, scaled, and rotated (also default). The rotation referred to here means that the final arrangement of points was rotated so that NMDS axis 1 captured as much variation as possible (aka: “varimax” rotation; McCune et al. (2002)).
The stress expresses how well the NMDS represented the rank order of the distance matrix. Lower stress indicates a more faithful representation. Stress increases as distances between samples are increased or decreased relative to the same distances in the original, full-dimensional space. If you picture the full-dimensional distances as ropes connecting the samples, and the amount of stretching or coiling of the ropes that happens as the samples are squashed into lower-dimensional space as the stress, then you pretty much have the idea.
There is no hard and fast rule, but in practice stress values should be >0 and <0.2. Some authors suggest that NMDS fits with stress \(\ge\) 0.2 are suspect and should not be interpreted; other authors use 0.1 as the cutoff. Some authors and software packages scale stress by 100, so the cutoff becomes 20 or 10 instead of 0.2 or 0.1 (McCune et al. 2002). Like P-values, stress values are a heuristic for inference and so you should not get too hung up on them. The stress plot and the screeplot are arguably more meaningful evaluations of your NMDS fit.
The stressplot below shows that the NMDS did a very good job representing the distance matrix in the reduced space, because the points are clustered near the line and the R2 values very high.
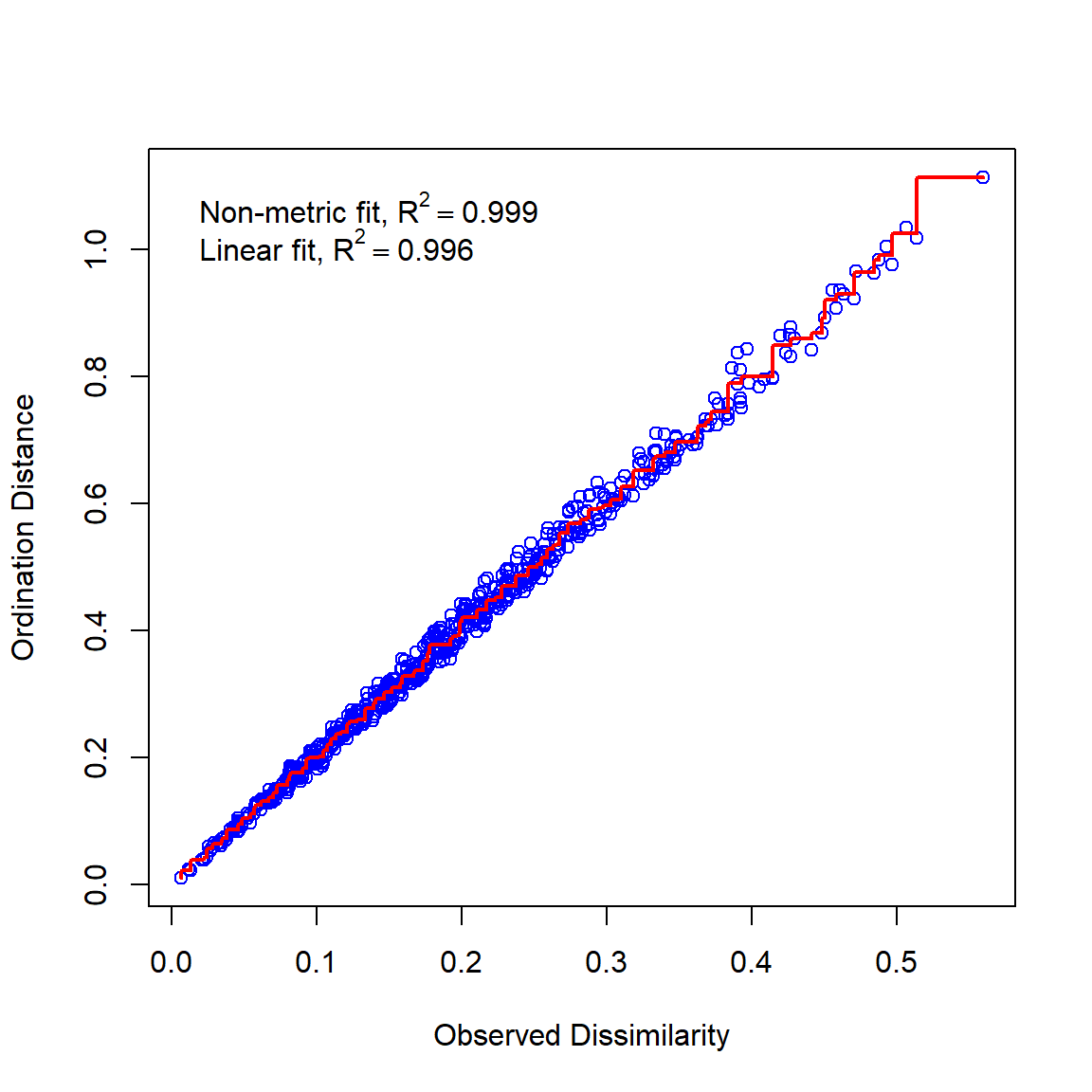
The screeplot shows how the stress of the ordination changes as more dimensions are added. An NMDS ordination with the same number of dimensions as the original data would have stress 0. Generally, adding dimensions decreases stress, but there is usually a point of diminishing returns.
For the example below, I added a few more dimensions to the dataset dat with no information so that a better screeplot could be constructed. You don’t need to do this to your own data—the only reason it’s being done here is because our dataset only had 3 dimensions to start with. With your data, you should fit NMDS ordinations with more dimensions than you think you need, to see how stress decreases with dimensionality.
# extra dimensions with random numbers (no information)
ext <- matrix(runif(n*1, 0, 0.1), nrow=n, ncol=2)
# combine with original data
dat2 <- cbind(dat, ext)
# fit NMDS ordinations in a loop
# for each element of nlist, k = number of dimensions
nlist <- vector("list", ncol(dat2))
for(i in 1:length(nlist)){
nlist[[i]] <- metaMDS(dat2, distance="euclidean", k=i)
}
# extract stress values for each NMDS fit
strs <- sapply(nlist, function(x){x$stress})# fancy plot
par(mfrow=c(1,1), cex.lab=1.2, cex.axis=1.2)
plot(1:length(nlist), strs, type="l", lwd=3,
xlab="Dimensions in NMDS",
ylab="Stress")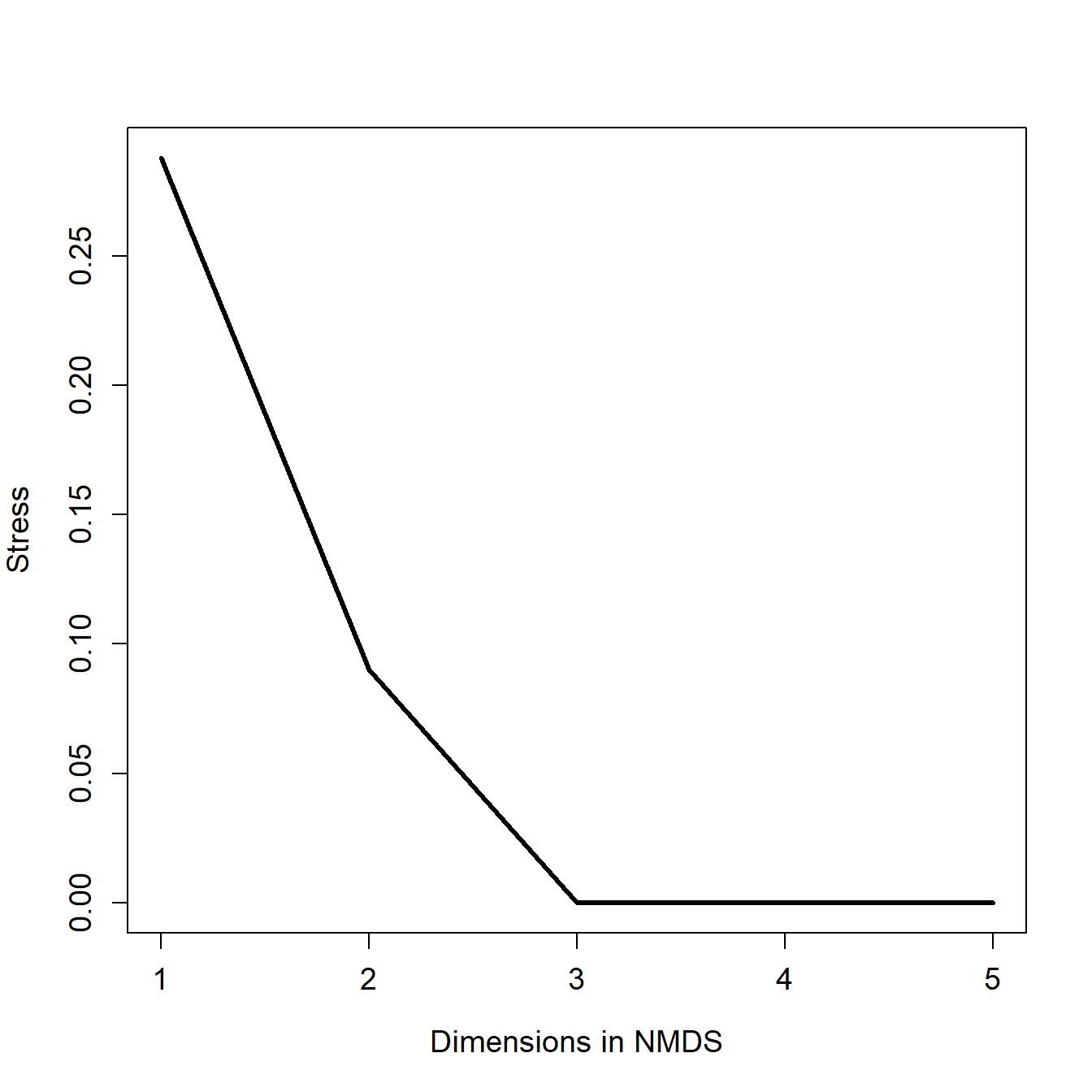
The screeplot shows that the stress decreases much more when going from 1 to 2 dimensions than it does for going from 2 to 3 dimensions. Stress becomes negligible for \(\ge\) 3 dimensions, because the original data had 3 dimensions and the two additional dimensions had almost 0 variance. The bend in the curve at k = 2 indicates that 2 is probably the optimal number of dimensions. If you’re not sure how many dimensions to use, examine biplots for both k and try to determine which plot is more interpretable biologically.
We can plot the scores of the samples much in the same way as we did the PCA scores in the previous example. We can also produce a biplot that works much the same way as the PCA biplot. We’ll explore those methods in the next section.
13.5.2.3 NMDS real data example
Load the dune dataset that comes with package vegan. This dataset contains cover class values for 30 species of plants on 20 dune meadow sites in the Netherlands. We’ll also load dune.env, the environmental data that describe each site.
If we are interested in in plant diversity among the sites, we could use multivariate methods to describe variation in plant cover. First, make some histograms of the cover of each plant species.
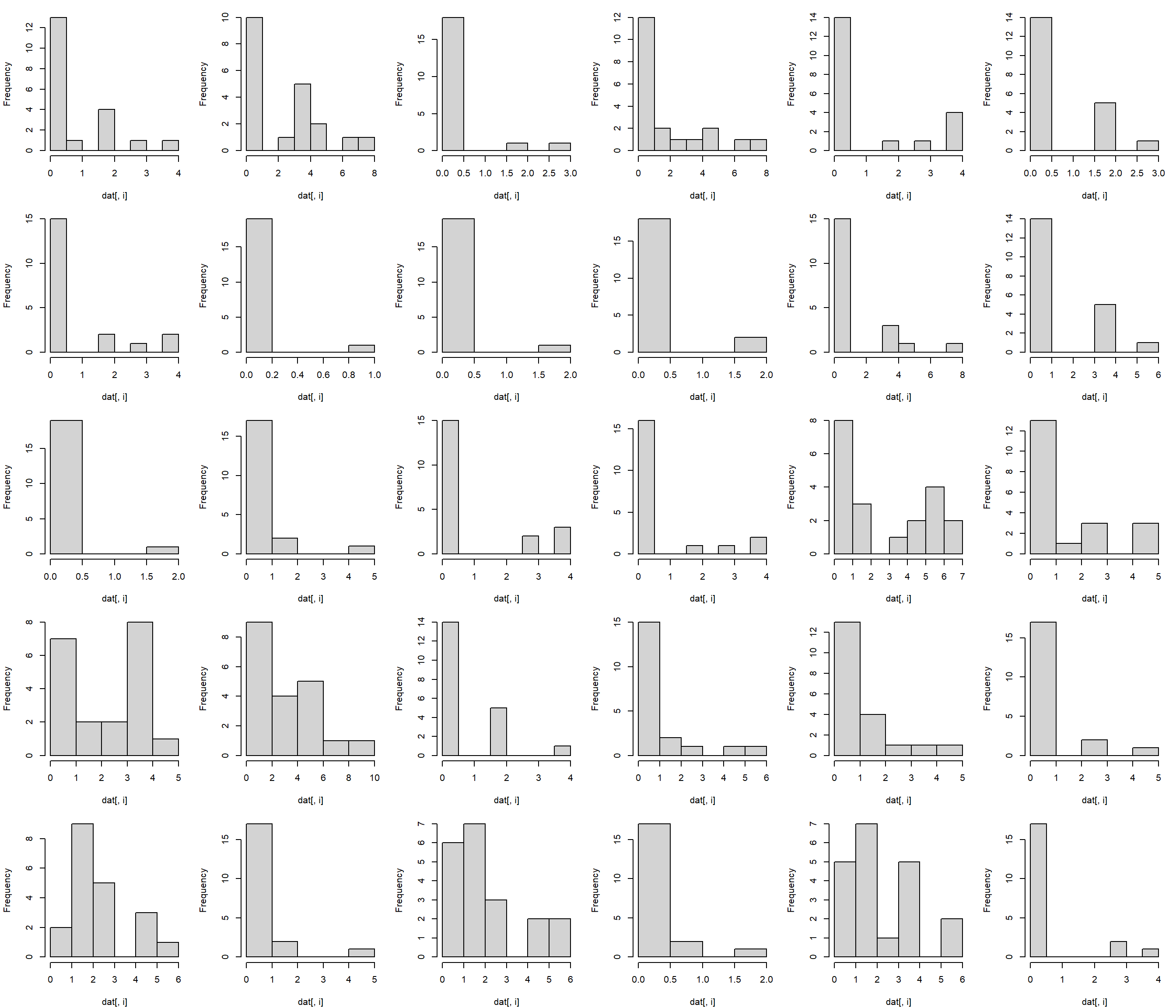
The cover of most species is clearly non-normal. This means that PCA would be difficult to fit. What’s more, the response variable (canopy cover class) isn’t really quantitative. Instead, it is ordinal. For example, category 2 represents greater proportion of plant cover than category 1, but it’s not clear how much more. So, an analysis based on rank order might make more sense than one based on actual values. That suggests using NMDS instead of PCA. Use vegan::metaMDS() to fit the NMDS, using the default Bray-Curtis distance metric.
## Run 0 stress 0.1192678
## Run 1 stress 0.1183186
## ... New best solution
## ... Procrustes: rmse 0.02027121 max resid 0.06496598
## Run 2 stress 0.1900911
## Run 3 stress 0.1192679
## Run 4 stress 0.19015
## Run 5 stress 0.1192678
## Run 6 stress 0.1183186
## ... New best solution
## ... Procrustes: rmse 9.438674e-06 max resid 3.090521e-05
## ... Similar to previous best
## Run 7 stress 0.1183186
## ... Procrustes: rmse 2.811111e-06 max resid 7.842694e-06
## ... Similar to previous best
## Run 8 stress 0.1192679
## Run 9 stress 0.1192678
## Run 10 stress 0.1192678
## Run 11 stress 0.1812933
## Run 12 stress 0.1889647
## Run 13 stress 0.1192679
## Run 14 stress 0.1192678
## Run 15 stress 0.1183186
## ... Procrustes: rmse 1.256982e-05 max resid 3.657271e-05
## ... Similar to previous best
## Run 16 stress 0.1192679
## Run 17 stress 0.1192678
## Run 18 stress 0.1192678
## Run 19 stress 0.1192678
## Run 20 stress 0.192224
## *** Best solution repeated 3 times##
## Call:
## metaMDS(comm = dat)
##
## global Multidimensional Scaling using monoMDS
##
## Data: dat
## Distance: bray
##
## Dimensions: 2
## Stress: 0.1183186
## Stress type 1, weak ties
## Best solution was repeated 3 times in 20 tries
## The best solution was from try 6 (random start)
## Scaling: centring, PC rotation, halfchange scaling
## Species: expanded scores based on 'dat'The NMDS fit has stress = 0.118, which is not too bad. Let’s take a look at the ordination.
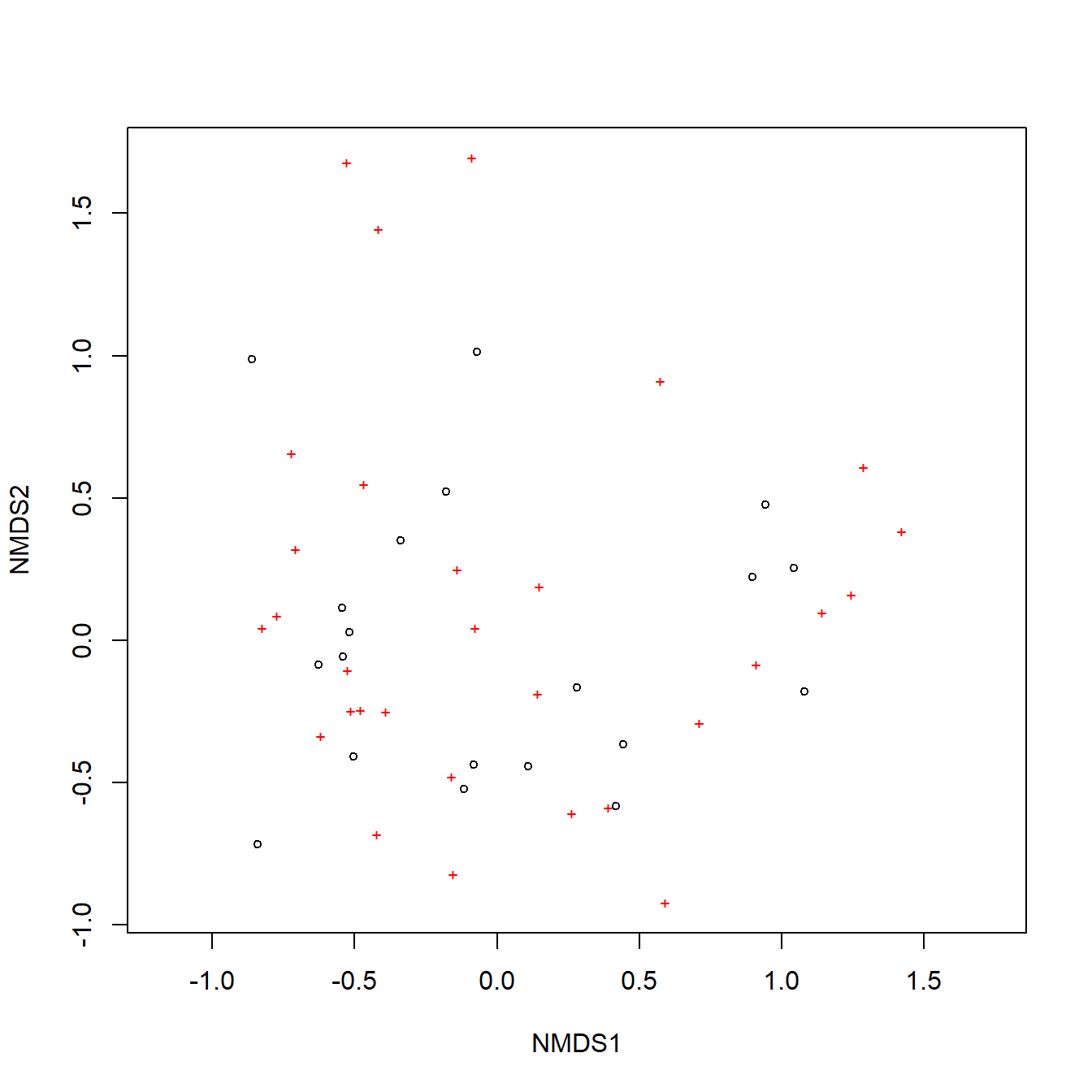
The default NMDS biplot is not very informative, so lets’ build the plot manually. While we’re at it, let’s use the environmental dataset to assign some category labels.
# management regimes
mans <- sort(unique(env$Management))
nman <- length(mans)
# land uses
uses <- sort(unique(env$Use))
nuse <- length(uses)
# colors and symbols
cols <- c("blue", "purple", "red")
pchs <- 15:18
env$col <- cols[match(env$Use, uses)]
env$pch <- pchs[match(env$Management, mans)]
# get site and species scores
px <- scores(p1, display="sites")
vx <- scores(p1, display="species")
# fancy plot
par(mfrow=c(1,1), mar=c(5.1, 5.1, 1.1, 1.1),
bty="n", las=1, lend=1,
cex.axis=1.3, cex.lab=1.3)
plot(px, pch=env$pch, col=env$col, cex=1.3,
xlim=c(-1.5, 1.5), ylim=c(-1.5, 1.5))
segments(0, 0, vx[,1], vx[,2])
mult <- 1.1
text(mult*vx[,1], mult*vx[,2], rownames(vx))
legend("bottomright", legend=mans, pch=pchs, cex=1.3)
legend("bottomleft", legend=uses, col=cols, pch=16, cex=1.3)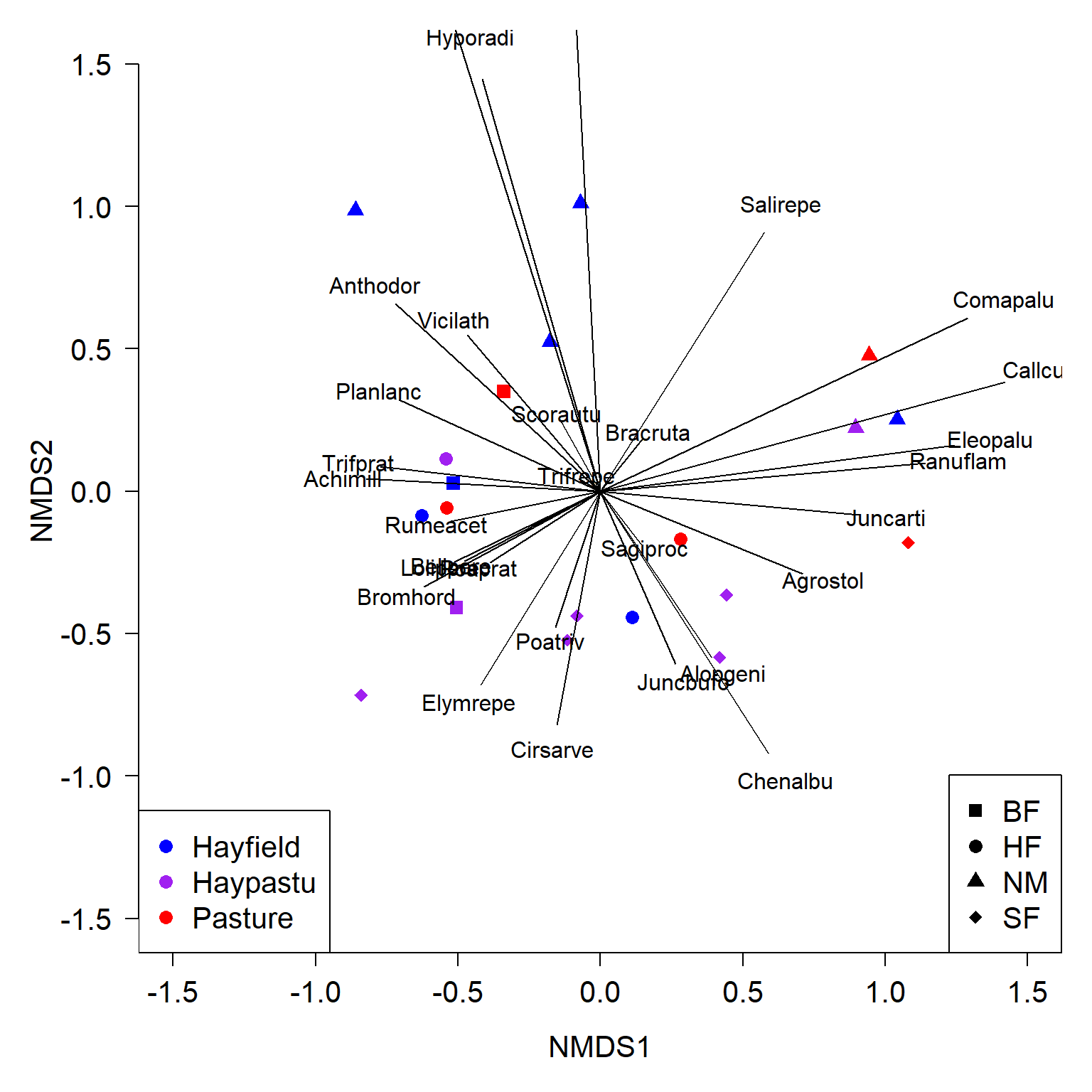
There’s a lot of information in that figure, so let’s break it down:
- Points show samples (sites).
- Proximity of two points reflects their dissimilarity in terms of the plant variables (closer = more similar).
- Point color encodes land use (hayfield, pasture, or both).
- Point shape encodes land management: BF (Biological farming), HF (Hobby farming), NM (Nature Conservation Management), and SF (Standard Farming).
- Vectors show how the species are associated with the ordination space. Species cover increases in the direction of the vector. For example, species “Juncarti” increases to the right and decreases to the left.
- Magnitude of each vector indicates the strength of the association. Vectors that are parallel to one of the NMDS axes are particularly interesting because they describe important gradients among the sites.
The figure is a bit of a mess, so we should try some different representations to help us make sense of it. Code one factor at a time:
par(mfrow=c(1,2))
cols1 <- rainbow(nuse)
cols1x <- cols1[match(env$Use, uses)]
plot(px, pch=16, col=cols1x, cex=1.3,
xlim=c(-1.5, 1.5), ylim=c(-1.5, 1.5))
legend("bottomright", legend=uses,
pch=16, col=cols1, cex=1.3)
cols2 <- rainbow(nman)
cols2x <- cols2[match(env$Management, mans)]
plot(px, pch=16, col=cols2x, cex=1.3,
xlim=c(-1.5, 1.5), ylim=c(-1.5, 1.5))
legend("bottomright", legend=mans,
pch=16, col=cols2, cex=1.3)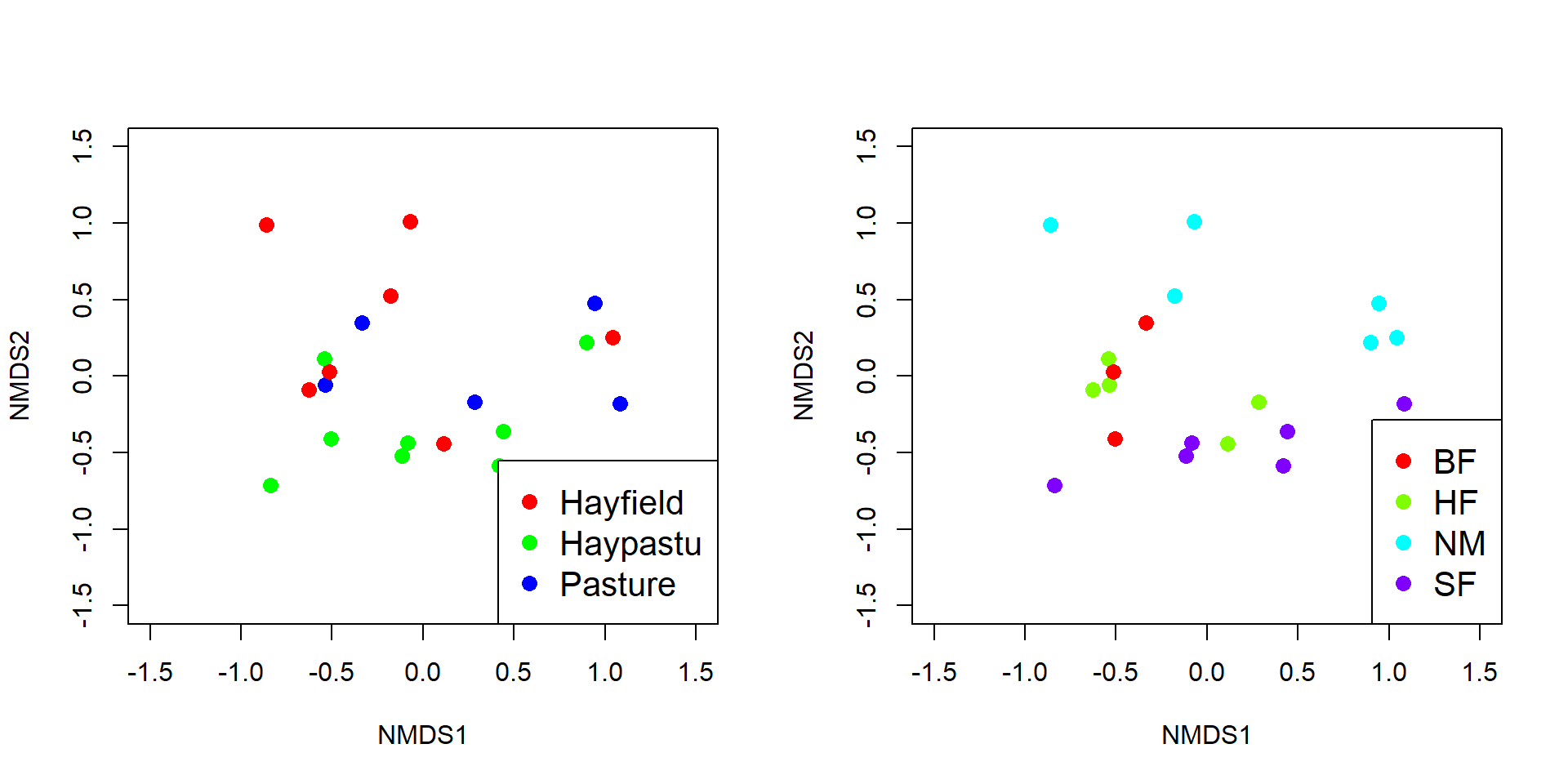
When only one factor is plotted, it’s a little easier to see the potential grouping by management style in the right panel. Styles SF, HF, and NM fall out mostly along NMDS2, but BF does not separate cleanly from the others. Let’s investigate the differences related to management styles.
We can add ellipses to help illustrate group centers (aka: “centroids”, or average positions in NMDS space) and the 95% CI of the centroids.
# define some colors
cols <- rainbow(nman)
colsx <- cols2[match(env$Management, mans)]
# make plot
par(mfrow=c(1,1))
plot(px, pch=16, col=colsx, cex=1.3,
xlim=c(-1.5, 1.5), ylim=c(-1.5, 1.5))
# add ellipse
ordiellipse(p1, env$Management,
kind="se", conf=0.95,
draw="polygon", col=cols, border=NA)
# plot group labels with white box behind at centroids
centx <- aggregate(p1$points[,1],
by=list(env$Management), FUN=mean)$x
centy <- aggregate(p1$points[,2],
by=list(env$Management), FUN=mean)$x
box.len <- 0.1 # fiddle with this to get boxes right size
rect(centx-box.len, centy-box.len,
centx+box.len, centy+box.len,
col="white", border="black")
text(centx, centy, mans, cex=1.3,
col=cols, font=2, adj=c(0.5, 0.45))
# add points again to make sure they show up
points(px, pch=21, bg=colsx, fg="black", lwd=2, cex=1.4)
legend("bottomright", legend=mans,
pch=21, pt.bg=cols, col="black", pt.lwd=2, cex=1.3)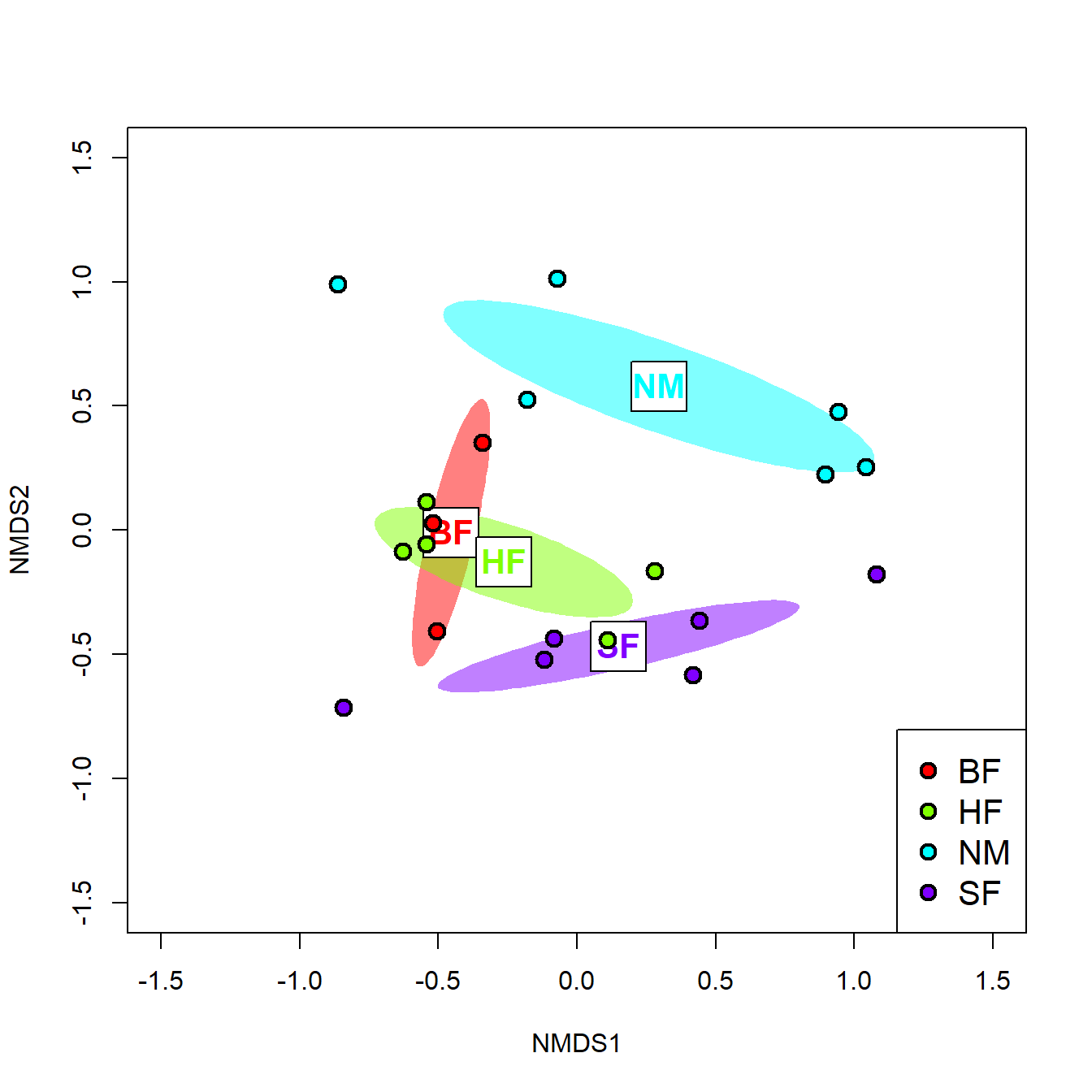
The default colors produced by rainbow() can be horrendous, but you get the idea. There are better ways to get color palettes that you can explore. The figure shows that it is quite likely that at least some of the management groups differ from each other in terms of their plant cover. We can test this directly with MRPP.
##
## Call:
## mrpp(dat = px, grouping = env$Management)
##
## Dissimilarity index: euclidean
## Weights for groups: n
##
## Class means and counts:
##
## BF HF NM SF
## delta 0.5279 0.5845 1.055 0.8339
## n 3 5 6 6
##
## Chance corrected within-group agreement A: 0.2216
## Based on observed delta 0.792 and expected delta 1.017
##
## Significance of delta: 0.004
## Permutation: free
## Number of permutations: 999The MRPP shows significant separation between the management groups, but the relatively low A indicates that there is still a lot of the positioning left unexplained.
We can also use NMDS to test for relationships between the NMDS coordinates and continuous variables using envfit() (from the vegan package). Note that only columns 1, 2, and 5 are used in the routine because those are the columns that contain quantitative (or ordinal) potential predictors.
##
## ***VECTORS
##
## NMDS1 NMDS2 r2 Pr(>r)
## A1 0.96474 0.26322 0.3649 0.014 *
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
## Permutation: free
## Number of permutations: 999
##
## ***FACTORS:
##
## Centroids:
## NMDS1 NMDS2
## Moisture1 -0.5101 -0.0403
## Moisture2 -0.3938 0.0139
## Moisture4 0.2765 -0.4033
## Moisture5 0.6561 0.1476
## Manure0 0.2958 0.5790
## Manure1 -0.2482 -0.0215
## Manure2 -0.3079 -0.1866
## Manure3 0.3101 -0.2470
## Manure4 -0.3463 -0.5583
##
## Goodness of fit:
## r2 Pr(>r)
## Moisture 0.5014 0.002 **
## Manure 0.4247 0.018 *
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
## Permutation: free
## Number of permutations: 999The output shows that all three of A1 soil horizon thickness (A1), moisture category, and manure category were significantly related to the NMDS configuration. The plots below show some ways to illustrate these relationships. First, we can add vectors representing continuous variables to the ordination. These vectors are exactly like biplot arrows for variables that went into the ordination, and are interpreted the same way . If you include both ordinated variables and other variables fitted with envfit(), you should make them different colors.
# get coordinates of vectors (matrix)
ef.vec <- ef$vectors$arrows
# plot points
par(mfrow=c(1,1))
plot(px, pch=16, cex=1.3,
xlim=c(-1.5, 1.5), ylim=c(-1.5, 1.5))
# add envfit vector
segments(0, 0, ef.vec[1,1], ef.vec[1,2], col="red", lwd=2)
# multiplier to move label outwards (should be >1)
mult <- 1.2
text(mult*ef.vec[1,1], mult*ef.vec[1,2],
rownames(ef.vec)[1], col="red")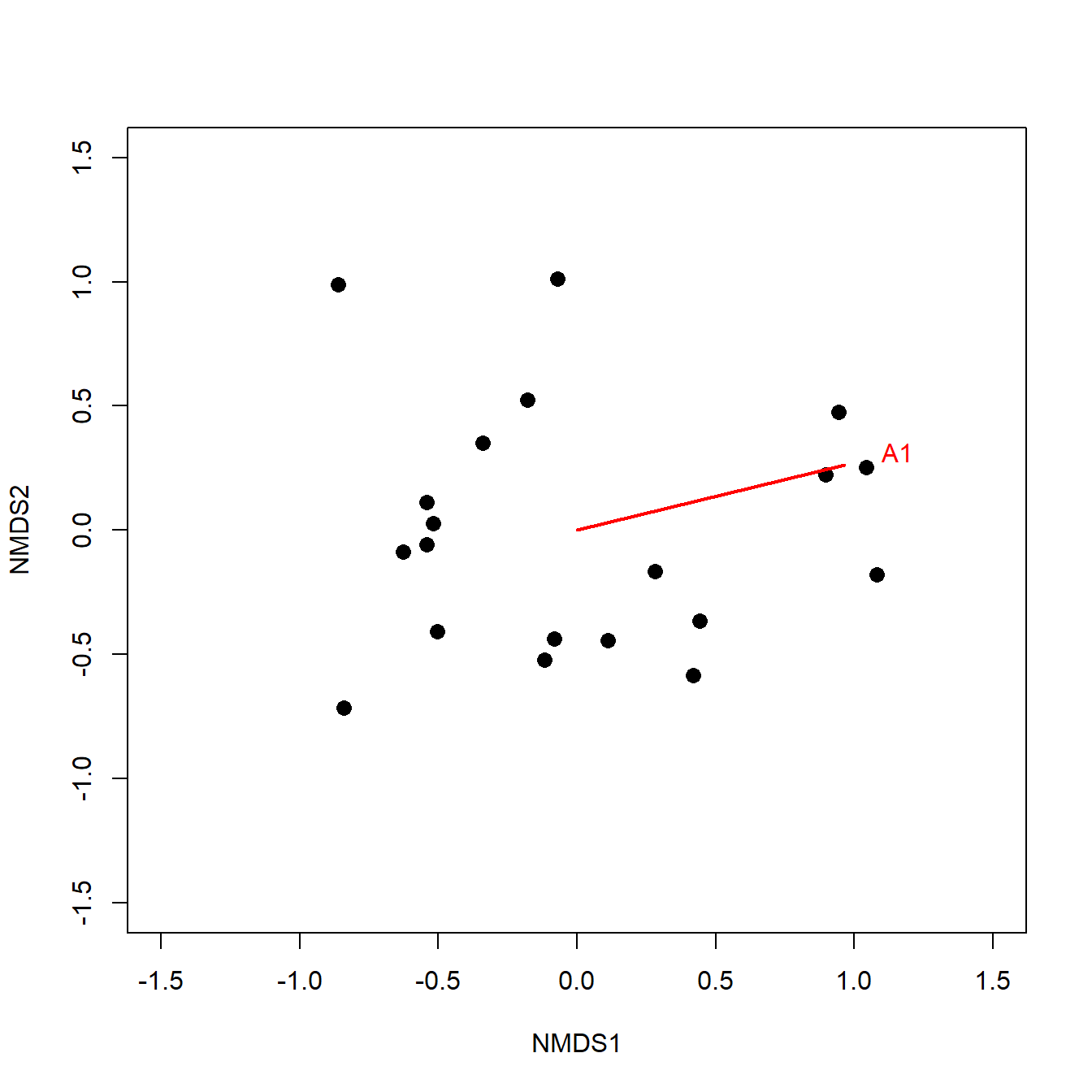
# not run:
# if more than one continuous envfit to plot:
#mult <- 1.2
#for(i in 1:nrow(ef.vec)){
# segments(0, 0, ef.vec[i,1], ef.vec[i,2],
# col="red", lwd=2)
# text(mult*ef.vec[i,1], mult*ef.vec[i,2],
# rownames(ef.vec)[i], col="red")
#}Factors that define groups, like the farming types above, can be encoded in the points by shape and/or color, and their uncertainty expressed with ellipses. Factors that are ordered, like Moisture and Manure, can be added to the plot as arrows. Adding arrows to connect centroids of the levels of an ordered factor is also a great way to show changes over time or space. For example, you could use season or year as an ordered factor to show changes over time; or, use latitude or elevation intervals as an ordered factor. Even if one of these variables is treated continuously, showing arrows by ordered groups (levels) can help capture nonmonotonic relationships that would be masked by a single envfit() vector. The figure below illustrates the difference between treating a continuous predictor, time, as an ordered factor vs. as a continuous variable.
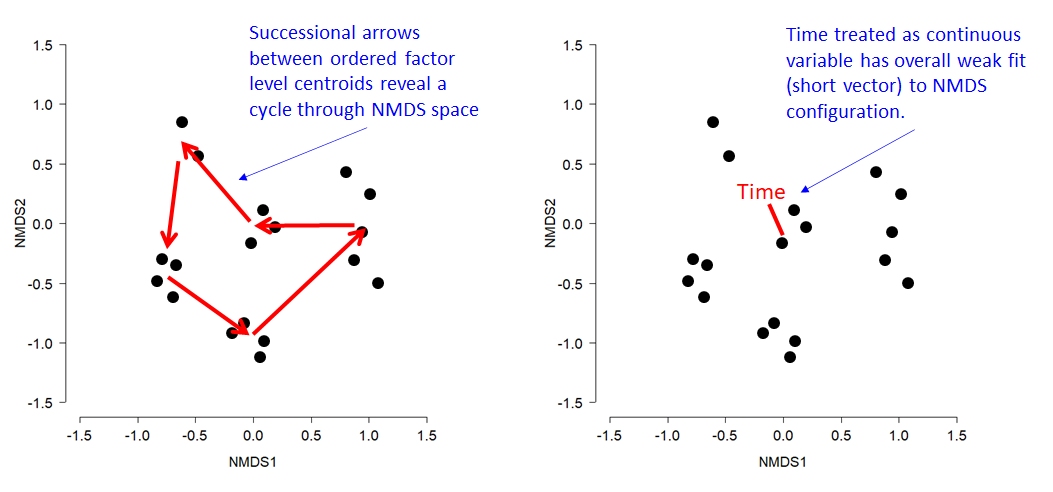
The code below shows how to extract the coordinates for the arrows showing levels of an ordered factor.
# get matrix of level centroids (has all factors)
ef.fac <- ef$factors$centroids
# isolate moisture and manure rows of matrix
ef.moi <- ef.fac[grep("Moist", rownames(ef.fac)),]
ef.man <- ef.fac[grep("Manure", rownames(ef.fac)),]
# number of levels of each factor
nmois <- nrow(ef.moi)
nmanu <- nrow(ef.man)
par(mfrow=c(1,1))
plot(px, pch=16, cex=1.3,
xlim=c(-1.5, 1.5), ylim=c(-1.5, 1.5))
# add arrows
# notice how arrows are specified from the matrix as
# beginning x, beginning y, ending x, and ending y, and
# how bracket notation is used.
arrows(ef.moi[-nmois,1], ef.moi[-nmois,2],
ef.moi[-1, 1], ef.moi[-1, 2], col="red",
lwd=3, length=0.15)
arrows(ef.man[-nmanu ,1], ef.man[-nmanu ,2],
ef.man[-1, 1], ef.man[-1, 2], col="blue",
lwd=3, length=0.15)
legend("topright",
legend=c("Moisture gradient", "Manure gradient"),
lwd=3, col=c("red", "blue"), bty="n", cex=1.3)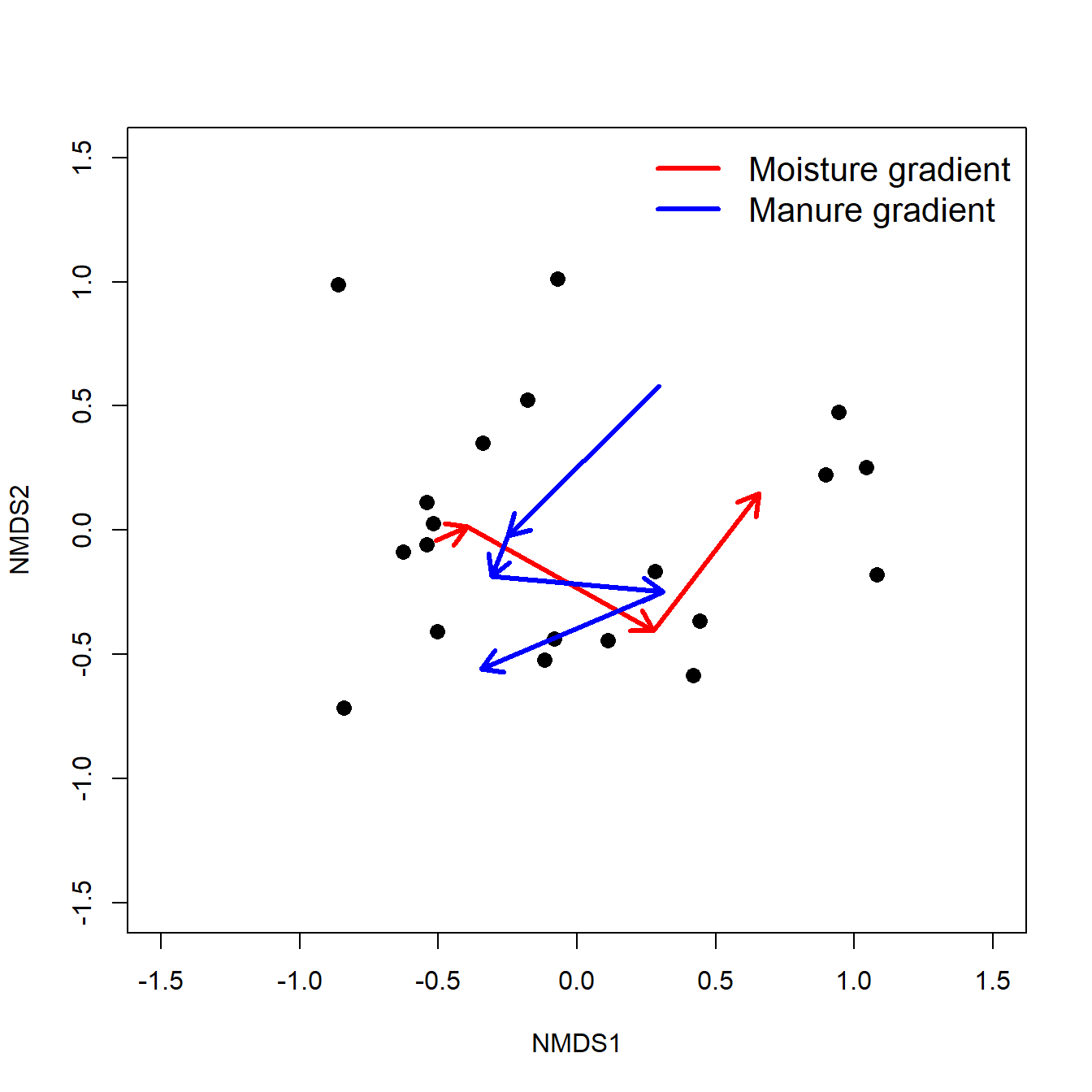
13.5.2.4 Hypothesis testing using NMDS
NMDS ordinations can also be used as the basis for hypothesis tests about the magnitude and direction of multivariate trends in experiments. If control and treated samples (or before and after samples) can be matched in pairs or groups, then the paths from the control/before to the treated/after samples can be thought of as the multivariate “response” to whatever the treatment was (McCune et al. 2002). This is because differences in position in NMDS space represent differences in terms of the original variables. The example below uses simulated data to illustrate the method.
- Left panel: NMDS ordination of samples. Arrows show change from “before” to “after”. Color of arrows signifies control treatment (black) or treated samples (red).
- Center panel: “Change vectors” translated so that they emanate from the origin. Magnitude of vector indicates magnitude of change from before to after treatment. Direction of vector indicates direction of change.
- Right panel: Change vectors translated to origin and scaled to unit length. Position of end points on unit circle indicate direction of change. In ecology these are also called “composition vectors” because they indicate changes in species composition regardless of magnitude of change.
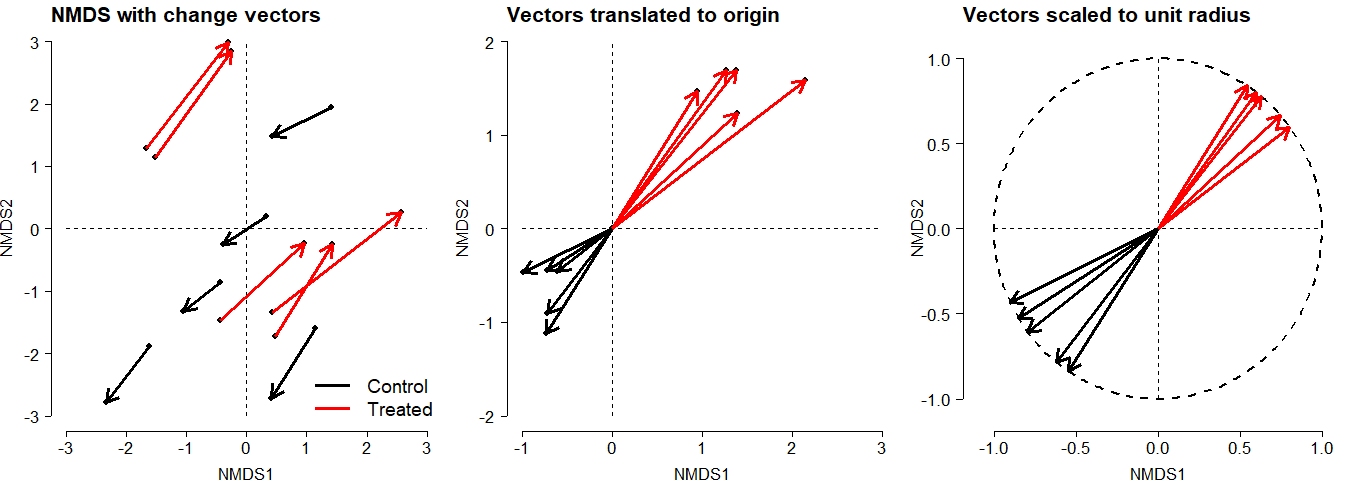
The positions of the vector endpoints in the center panel can be used to test hypotheses about the overall change in the response variable matrix in response to treatment. An MRPP or other multivariate test such as PERMANOVA can be used to compare the locations of treatment groups in NMDS space. Differences in location in the center plot reflect both magnitude and direction of change.
Similarly, the positions of the composition vectors in the right panel can be used to test hypotheses about changes in the response variable matrix in response to treatment. Unlike the center panel, the differences in position in the right panel reflect direction of change only.
13.5.3 Other ordination techniques
PCA and NMDS were explored in detail because they are two of the most commonly used and applicable ordination techniques for biologists. There are other techniques out there that you may find useful but are beyond the scope of the course.
Principal coordinates analysis (PCoA) is a variation of PCA that can use any kind of distance metric. In one sense PCA uses the Euclidean distance metric because of its reliance on least squares. PCoA can use any distance metric, which may be desirable for data that do not meet the linearity and normality assumptions of PCA. PCoA works by converting distances into the elements of the crossproducts matrix S, which basically “pretends” that non-Euclidean distances are Euclidean.
Canonical ordination techniques simultaneously analyze two data matrices. Canonical ordination methods can be symmetric or asymmetric. In asymmetric methods, there is a response dataset and a predictor dataset. Reversing the roles of the matrices will change the outcome of the analysis. In contrast, symmetric methods treat both matrices the same. That is, in a symmetric ordination analysis, neither matrix is considered the “response” or “predictor” dataset. Reversing the roles of the matrices will not change the outputs.
13.5.3.1 Canonical asymmetric methods
Canonical asymmetric methods produce ordinations of a response matrix Y that are constrained to be linearly related to a second set of variables, the predictor matrix X.
Redundancy analysis (RDA) is an extension of multiple regression that models multivariate rather than univariate response values. Each ordination axis in RDA is called a “canonical axis” and is similar to a principal component. Each canonical axis in the response matrix Y is maximally related to a linear combination of variables in the predictor matrix X. RDA preserves the Euclidean distances among samples; this is a consequence of the relationship between RDA and multiple linear regression.
Canonical correspondence analysis (CCorA) is similar to RDA, but preserves a different distance metric (\(\chi^{2}\) or “chi-squared”) among the samples. CCorA may thus be more appropriate than RDA when data are nonnormal or when relationships are nonlinear.
Linear discriminant analysis (LDA) identifies linear combinations of variables in a predictor matrix X that classify observations in a response matrix Y. LDA can be thought of loosely as a multivariate analogue to multiple logistic or multinomial regression. Classification trees may present a more robust alternative to LDA in many situations.
13.5.3.2 Canonical symmetric methods
Canonical correlation analysis (CCA) is a constrained ordination technique where the ordination of one matrix is informed by multiple regression on another matrix. Given two data matrices A and B, with correlations among variables in A and B, CCA fits an ordination for both A and B where the canonical axes of each ordination are correlated with variables in the other matrix. In other words, CCA finds gradients in one matrix and tries to explain them in terms of information from another matrix. CCA is a powerful tool for exploratory analysis but can be confusing to fit and interpret.
Co-inertia analysis (CoIA) and Procrustes analysis (Proc) both seek ordinations of two data matrices A and B that represent relationships in both A and B simultaneously. CoIA and Proc work very differently but answer a similar question: how can samples be arranged in a reduced dimension space that preserves distances in terms of two sets of variables?
These techniques are described by Legendre and Legendre (2012) and McCune et al. (2002). The former reference has a more thorough mathematical treatment; the latter is more introductory. Both are excellent. Several newer references (Legendre and Legendre 2012, Borcard et al. 2018) include R code for implementing the methods.
Literature Cited
Because position is expressed in latitude and longitude, it is implicit that these are positions on a sphere. Euclidean distance between coordinates is assumes that the coordinates are on a plane, and so will be distorted. The distances are also in nonsensical units that combine degrees latitude and longitude, which are not interchangeable. If you ever need to calculate exact distances between geographic locations, transform the coordinates into a projected coordinate system like UTM (which will be in meters, by definition). Or, use the GIS functions in R which can work in spherical coordinates. Despite being incorrect from a GIS perspective, the distances calculated here are close enough for demonstrating NMDS.↩︎